Continuando nossa série de posts sobre o AKS, hoje vamos entender como o AKS cria os recursos no Azure. Se você não viu o post anterior mostrando como podemos criar um cluster de maneira rápida e fácil dentro do Azure, segue o link abaixo:
Quando você executa a criação de um cluster de Kubernetes no Azure, automaticamente a Microsoft cria diversos componentes, hoje vamos entender que componentes são esses criados pelo Azure e como eles se relacionam com o cluster de Kubernetes.
Estrutura
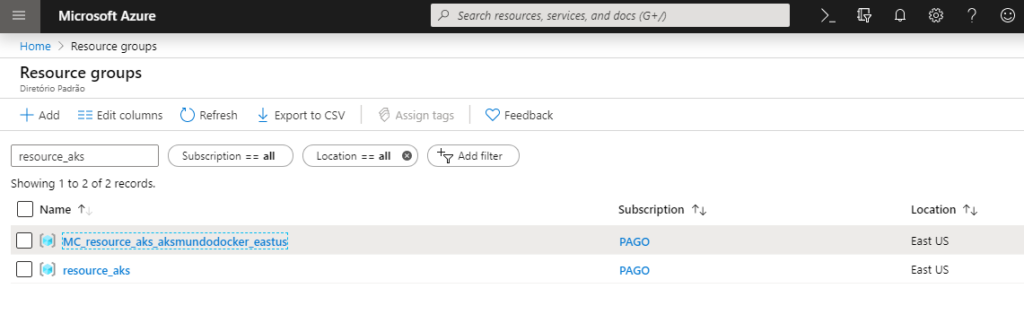
Na criação de um cluster simples igual foi criado no post anterior a Microsoft irá automaticamente no Azure criar recursos dos tipos: Load Balancer, Resource Group, Node Pools.
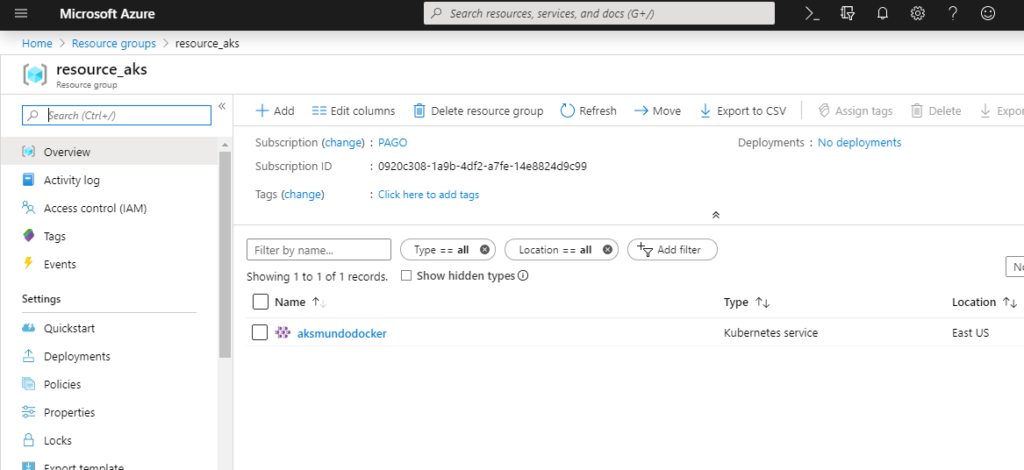
Na imagem acima é possível ver que em Resource Groups existem dois recursos, o resource_aks foi criado anteriormente, porem o MC_resource_aks_aksmundodocker_eastus é criado automaticamente pelo Azure e nesse momento não podemos renomear esse resource, então ele vai adicionar o prefixo: MC_{NOME DO RESOURCE GROUP}_{NOME DO CLUSTER}_{REGIÃO}. Dentro desse Resource Group é onde ficam os objetos criados especificamente para o cluster. Dentro do resource_aks você irá visualizar apenas um recurso do tipo Kubernetes Service, como na imagem abaixo:
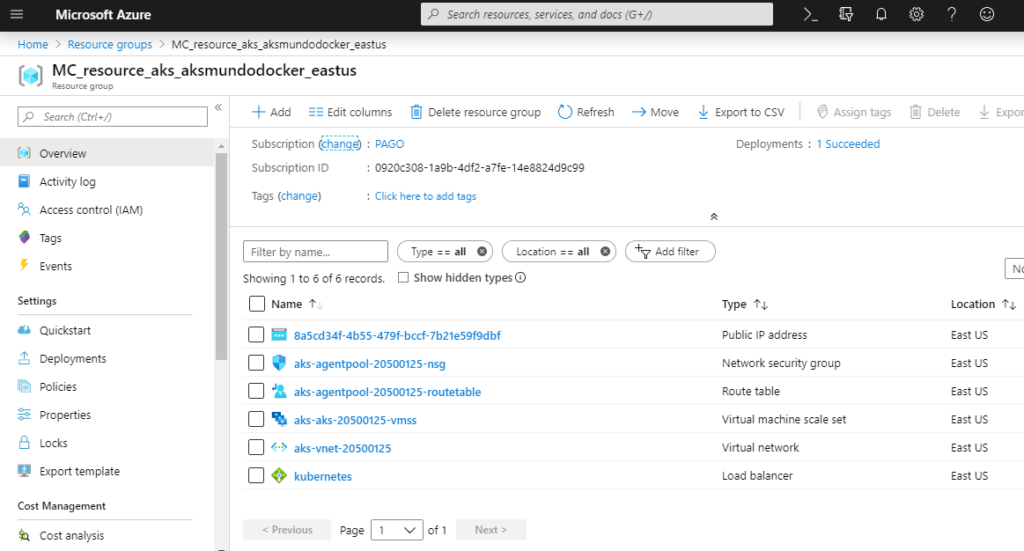
Ao clicar em MC_resource_aks_aksmundodocker_eastus você poderá ver os recursos criados, se você copiou e colocou o exemplo de criação do post anterior, você deve ver algo parecido com isto:
É possível ver os tipos de recursos: Public IP address, Network security group, Route table, Virtual machine scale set, Virtual network e Load balancer. Por padrão são esses os tipos de recursos criados para um cluster de AKS.
Public IP address
Quando se cria um cluster de AKS padrão o endereço IP padrão para o Load Balancer é um IP público, então automaticamente o Azure cria um recursos do tipo Public IP address dentro do Resource group.
Network security group
O Networ security group (NSG) é um componente do Azure no qual é possível criar as regras para tráfego nas interfaces de rede, definindo assim se habilita o tráfego para determinado endereço ou recurso ou se habilita o mesmo.
Route table
O Route table como o nome já sugere é um recurso do Azure para definir a tabela de roteamento de alguns componentes.
Virtual machine scale set
Para conseguir realizar o dimensionamento de máquinas de maneira automática o Azure cria para o cluster de AKS um recurso do tipo Virtual machine scale set que faz com que o grupo de máquinas pode aumentar ou diminuir conforme a demanda de uso ou o agendamento criado.
Virtual network
Todo o cluster de AKS precisa ser criado dentro de uma Virtual network (VNET) ela pode ser criada automaticamente no momento de criação do cluster (Igual a gente fez) ou pode ser criada anteriormente e depois informada no momento da criação do cluster.
Load balancer
Dentro do Kubernetes existem 3 tipos de services: NodePort, ClusterIP e Load balancer. Quando o tipo de service Load balancer é criado o Azure atribui 1 IP da sua subnet para esse service e configura no recurso Load balancer um encaminhamento para esse service. Nos próximos posts a gente vai entender melhor e ver como essas regras são criadas.
OBS* Os recursos criados pelo AKS de maneira automática não devem ser modificados ou excluídos por outras contas a não ser pela própria Azure, pois qualquer modificação pode fazer com que o recurso pare de funcionar e a Azure não de suporte a eles.
Os recursos acima são os criados de maneira default em um cluster simples no AKS. Agora que você aprendeu como funciona a estrutura do AKS e quais são os componentes básicos do cluster nos próximos posts você vai aprender como é possível realizar o deploy das aplicações, fazer integrações, monitoramento e obter o melhor desempenho para as suas aplicações em produção.
Trabalha em uma consultoria com foco em Plataforma como Serviço (PaaS), é especialista em Cloud Computing e Conteinerização, desenvolve todo dia uma nova maneira de resolver problemas e criar coisas novas.
Bora falar de facilidades? Então, o objetivo deste post é trazer uma introdução ao uso da Amazon EKS (Elastic Kubernetes Service), vamos entender melhor o que é essa ferramenta e como você pode começar a “brincar” com ela de forma simples e rápida.
Ahhh mas antes, você sabe o que é Kubernetes? Caso ainda não esteja familiarizado recomendo que leias os posts que fizemos sobre o assunto 😉 Segue os links:
O Elastic Kubernetes Service nada mais é do que uma forma de você poder ter um cluster (ou mais) de Kubernetes sob demanda e sem a necessidade de administração dos managers (que para muitos é o mais complexo e oneroso dentro do Kubernetes), ou seja, a Amazon mais uma vez disponibiliza mais uma facilidade e tira um peso de quem precisa gerenciar o ambiente, é claro que isso gera outros pontos de atenção, como é o caso do vendor lockin, porém, se bem pensado, pode ser uma decisão que valha a pena.
Como Funciona
O objetivo da Amazon é disponibilizar para você uma infraestrutura completa, inclusive, no caso do EKS, tendo o gerenciamento dos manager sendo realizado pela própria Amazon.
Temos então basicamente três pontos principais nessa arquitetura:
Manager
Você não terá acesso a essa estrutura, toda a gerencia e configuração fica por conta da AWS mesmo, então, menos um ponto para se preocupar.
Workers:
São os nós do cluster onde você poderá executar todos os seus conteirners, ou seja, quando você instanciar um novo pod, ele será provisionado em um desses hosts.
Client:
Você precisa ter o binário do kubectl no host para poder geranciar o cluster, e ai que vem um ponto bem legal, você gerencia o cluster de forma transparente, da mesma forma como se fosse um Kubernetes on premise.
Mãos a obra?
A criação do master pode ser realizado utilizando a console da AWS mesmo, CloudFormation ou via CLI, o que veremos hoje será via CLI pois é o mais simples, para isso, você deve ter configurado em seu computador o awscli, para isso, siga os passos: https://docs.aws.amazon.com/pt_br/cli/latest/userguide/cli-chap-install.html, para resumir, se seu host for linux, siga a sequência:
Instale o Python 3:
apt-get/yum install python3
Baixe o pip para instalar o aws cli:
curl -O https://bootstrap.pypa.io/get-pip.py
Instale o pip:
python get-pip.py --user ou python3 get-pip.py --user
Adicione um novo caminho em seu path:
export PATH=~/.local/bin:$PATH
source ~/.bash_profile
Instale o AWS Cli:
pip3 install awscli --upgrade --user
Verifique a instalação:
aws version
Feito isso, você precisa configurar o cli para as credenciais da AWS, para isso, execute os passos:
aws configure
Informe os dados conforme for sendo lhe solicitado e pronto, basta seguir para o próximo passo.
Você precisará configurar o aws-iam-authenticator, para isso, siga:
Dessa forma o eksctl criará toda a escrutura necessária para o funcionando do cluster, desde VPC até regras de security group, esse novo cluster será formado com 3 instâncias t3.medium. O retono do comando será algo parecido com este:
[ℹ] using region us-west-2
[ℹ] setting availability zones to [us-west-2b us-west-2c us-west-2d]
[ℹ] subnets for us-west-2b - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for us-west-2c - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for us-west-2d - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] nodegroup "standard-workers" will use "ami-0923e4b35a30a5f53" [AmazonLinux2/1.12]
[ℹ] creating EKS cluster "prod" in "us-west-2" region
[ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-west-2 --name=prod'
[ℹ] building cluster stack "eksctl-prod-cluster"
[ℹ] creating nodegroup stack "eksctl-prod-nodegroup-standard-workers"
[✔] all EKS cluster resource for "prod" had been created
[✔] saved kubeconfig as "/Users/ericn/.kube/config"
[ℹ] adding role "arn:aws:iam::111122223333:role/eksctl-prod-nodegroup-standard-wo-NodeInstanceRole-IJP4S12W3020" to auth ConfigMap
[ℹ] nodegroup "standard-workers" has 0 node(s)
[ℹ] waiting for at least 1 node(s) to become ready in "standard-workers"
[ℹ] nodegroup "standard-workers" has 2 node(s)
[ℹ] node "ip-192-168-22-17.us-west-2.compute.internal" is not ready
[ℹ] node "ip-192-168-32-184.us-west-2.compute.internal" is ready
[ℹ] kubectl command should work with "/Users/ericn/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "prod" in "us-west-2" region is ready
Ahh mas eu quero personalizar… Não se preocupe amigo, o eksctl permite você definir qual VPC vai usar, quais subnet, security group, imagem (desde que homologada pela AWS), chave, dentre outras opções.
Depois de criado o cluster, bem, agora ficou fácil, basta você administrar da mesma forma como se fosse um cluster de Kubernetes instalado ai, nas suas máquinas locais ;).
Valide se tudo está ok com o cluster executando os comandos para verificar os nós do cluster:
kubectl get nodes
Você pode visualizar se foi criado o serviço default também, para isso:
kubectl get svc
O retorno será algo parecido com este:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/kubernetes ClusterIP 10.100.0.1 443/TCP 1m
Legal, e agora?
Bem, agora a sua imaginação é limite, encare o EKS como um cluster normal, neste sentido, o deploy de suas apps seguirá o mesmo processo, e caso você queria, pode utilizar outras facilidades da AWS para agilizar a publicação, mas isso é conto para outro post.
Queremos ainda, falar sobre monitoramento no EKS, Logs, e claro, vamos criar e fazer deploy de alguns serviço neste cluster, vamos ver como ficam as questões de segurança, ingress de serviço, dentre outros pontos.
Eai, curtiu? Então manda para alguém que talvez tenha interesse, e claro, fique a vontade para conversamos 😉 Grande Abraço!
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.
Começamos 2019 e ficou bem claro que o Docker Swarm perdeu para o Kubernetes na guerra de orquestradores de contêineres.
Não vamos discutir aqui motivos, menos ainda se um é melhor que outro. Cada um tem um cenário ótimo para ser empregado como já disse em algumas das minhas palestras sobre o assunto. Mas de uma maneira geral se considerarmos o requisito evolução e compararmos as duas plataformas então digo que se for construir e manter um cluster de contêineres é melhor já começarmos esse cluster usando Kubernetes.
O real objetivo desse artigo é mostrar uma das possíveis abordagens para que nossas aplicações hoje rodando num cluster Docker Swarm, definidas e configuradas usando o arquivo docker-compose.yml possam ser entregues também em um cluster Kubernetes.
Intro
Já é meio comum a comparação entre ambos e posso até vir a escrever algo por aqui mas no momento vamos nos ater a um detalhe simples: cada orquestrador de contêineres cria recursos próprios para garantir uma aplicação rodando. E apesar de em alguns orquestradores recursos terem o mesmo nome, como o Services do Docker Swarm e o Services do Kubernetes eles geralmente fazem coisas diferente, vem de conceitos diferentes, são responsáveis por entidades diferentes e tem objetivos diferentes.
O Kompose, uma alternativa
O kompose é uma ferramenta que ajuda muito a converter arquivos que descrevem recursos do Docker em arquivos que descrevem recursos do Kubernetes e até dá para utilizar diretamente os arquivos do Docker Compose para gerir recursos no Kubernetes. Também tenho vontade de escrever sobre ele, talvez em breve, já que neste artigo vou focar em como ter recursos do Docker Swarm e do Kubernetes juntos.
Um pouco de história
Sempre gosto de passar o contexto para as pessoas entenderem como, quando e onde foram feitas as coisas, assim podemos compreender as decisões antes de pré-julgarmos.
Na Dockercon européia de 2017, a primeira sem o fundador Solomon Hykes, foi anunciado e demostrado como usar um arquivo docker-compose.yml para rodar aplicações tanto num cluster Docker Swarm quanto num cluster Kubernetes usando a diretiva Stacks.
A demostração tanto na Dockercon quanto no vídeo acima foram sensacionais. Ver que com o mesmo comando poderíamos criar recursos tanto no Docker Swarm quanto no Kubernetes foi um marco na época. O comando na época:
Só tinha um problema, isso funcionava apenas em instalações do Docker Enterprise Edition ($$$) ou nas novas versões do Docker for Desktop que eram disponíveis apenas para OSX e Windows.
Aí você pergunta: Como ficaram os usuário de Linux nessa história, Wsilva?
Putos, eu diria.
Protecionismo?
Assim como outros também tentei fazer uma engenharia reversa e vi que o bootstrap desse Kubernetes rodando dentro do Docker for Mac e Windows era configurado usando o Kubeadm. Fucei, criei os arquivos para subir os recursos Kubernetes necessários e quase consegui fazer rodar mas ainda me faltava descobrir como executar o binário responsável por extender a api do Kubernetes com os parâmetros certos durante a configuração de um novo cluster, todas as vezes que rodei tive problemas diferentes.
Até postei um tweet a respeito marcando a Docker Inc mas a resposta que tive foi a que esperava: a Docker não tem planos para colocar suporte ao Compose no Linux, somente Docker for Desktop e Enterprise Edition.
Ainda bem antes de tentar fazer isso na mão, lá na Dockercon de 2018 (provavelmente também escreverei sobre ela) tive a oportunidade de ver algumas palestras sobre extender a API do Kubernetes, sobre como usaram Custom Resource Definition na época para fazer a mágica de interfacear o comando docker stack antes de mandar a carga para a API do Kubernetes ou para a API do Docker Swarm e também conversei com algumas pessoas no conference a respeito.
A desculpa na época para não termos isso no Docker CE no Linux era uma questão técnica, a implementação dependeria muito de como o Kubernetes foi instalado por isso que no Docker para Desktop e no Docker Enterprise, ambientes controlados, essa bruxaria era possível, mas nas diversas distribuíções combinadas com as diversas maneiras de criar um cluster Kubernetes seria impossível prever e fazer um bootstrap comum a todos.
Docker ainda pensando no Open Source?
Na Dockercon européia de 2018, praticamente um ano depois do lançamento do Kubernetes junto com o Swarm finalmente foi liberado como fazer a API do Compose funcionar em qualquer instalação de Kubernetes. Mesmo sem as instruções de uso ainda mas já com os fontes do instalador disponíveis (https://github.com/docker/compose-on-kubernetes) era possível ver que a estrutura tinha mudado de Custom Resource Definition para uma API agregada e relativamente fácil de rodar em qualquer cluster Kubernetes como veremos a seguir.
Mão na massa.
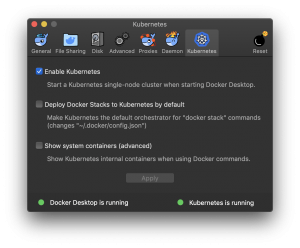
Para rodarmos essa API do Compose no Mac e no Windows, assim como no final de 2017, basta habilitar a opção Kubernetes na configuração conforme a figura e toda a mágica vai acontecer.
No Linux podemos trabalhar com o Docker Enterprise Edition ou com o Docker Community Edition.
Para funcinar com o Docker Community Edition primeiramente precisamos de um cluster pronto rodando kubernetes e podemos fazer teoricamente em qualquer tipo de cluster. Desde clusters criados para produção com Kops – (esse testei na AWS e funcionou), ou Kubespray, ou em clusteres locais como esse que criei para fins educativos: https://github.com/wsilva/kubernetes-vagrant/ (também funcionou), ou Minikube (também funcionou, está no final do post), ou até no saudoso play with kubernetes (também funcionou) criado pelo nosso amigo argentino Marcos Nils.
Para verificar se nosso cluster já não está rodando podemos checar os endpoints disponíveis filtrando pela palavra compose:
$ kubectl api-versions | grep compose
Pré requisitos
Para instalar a api do Compose em um cluster Kubernetes precisamos do etcd operator rodando e existem maneiras de instalar com e sem suporte a SSL. Mais informações podem ser obtidas nesse repositório.
Neste exemplo vamos utilizar o gerenciador de pacotes Helm para instalar o etcd operator.
Instalação
Primeiro criamos o namespace compose em nosso Kubernetes:
Se estivermos utilizando OSX, podemos instalar de maneira simples com homebrew.
$ brew install kubernetes-helm
Updating Homebrew...
Error: kubernetes-helm 2.11.0 is already installed
To upgrade to 2.12.3, run `brew upgrade kubernetes-helm`
$ brew upgrade kubernetes-helm
Updating Homebrew...
==> Upgrading 1 outdated package:
kubernetes-helm 2.11.0 -> 2.12.3
==> Upgrading kubernetes-helm
==> Downloading https://homebrew.bintray.com/bottles/kubernetes-helm-2.12.3.moja
######################################################################## 100.0%
==> Pouring kubernetes-helm-2.12.3.mojave.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==> Summary
? /usr/local/Cellar/kubernetes-helm/2.12.3: 51 files, 79.5MB
No Linux podemos optar por gerenciadores de pacotes ou instalar manualmente baixando o pacote e colocando em algum diretório do PATH:
$ curl -sSL https://storage.googleapis.com/kubernetes-helm/helm-v2.12.1-linux-amd64.tar.gz -o helm-v2.12.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.12.1-linux-amd64.tar.gz
x linux-amd64/
x linux-amd64/tiller
x linux-amd64/helm
x linux-amd64/LICENSE
x linux-amd64/README.md
$ cp linux-amd64/tiller /usr/local/bin/tiller
$ cp linux-amd64/helm /usr/local/bin/helm
Estamos em 2019 então todos os clusters Kubernetes já deveriam estar rodando com RBAC (Role Base Access Control) por questões de segurança. Para isso devemos criar uma Service Account em nosso cluster para o tiller.
Neste exemplo fizemos o bind para o role cluster admin, mas seria interessante criar uma role com permissões mais restritas definindo melhor o que o helm pode ou não fazer em nosso cluster Kubernetes.
Podemos usar tando o kubectl como o docker cli para checar os status:
$ kubectl get stacks
NAME SERVICES PORTS STATUS CREATED AT
demo-stack 3 web: 80 Available (Stack is started) 2019-01-28T20:47:38Z
$ docker stack ls \
--orchestrator=kubernetes
NAME SERVICES ORCHESTRATOR NAMESPACE
demo-stack 3 Kubernetes default
Podemos pegar o ip da máquina virtual rodando minikube com o comando minikube ip e a porta do serviço web-published e acessar no nosso navegador.
Se você está pensando em migrar seus workloads de clusters de Docker Swarm para clusters de Kubernetes você pode optar tanto pelo Kompose quanto pelo Docker Compose no Kubernetes.
Optando pelo Compose no Kubernetes podemos usar o Docker for Mac ou Docker for Windows, basta habilitar nas configurações a opção de cluster Kubernetes.
Se estiver no Linux pode optar por seguir os passos acima ou pagar pelo Docker Enterprise Edition.
Veja como cada uma dessas opções se adequa melhor aos seus processos e divirta-se.
Conhecido como Boina, Tom e Wsilva entre outros apelidos. Possui certificações Docker Certified Associate e ZCE PHP 5.3, autor do livro Aprendendo Docker, do básico à orquestração de contêineres publicado pela editora Novatec. Docker Community Leader em São Paulo, tem background em telecomunicações, programação, VoIP, Linux e infraestrutura.
Fala pessoal, estamos aqui novamente para continuar nossa série que fala sobre Kubernetes. Abaixo coloquei a lista de posts criados até o momento referente a Kubernetes, então se não tinha visto o ínicio é só clicar abaixo e ler cada um dos posts.
Então, o que é ConfigMap? É o desacoplamento dos artefatos de configuração do conteúdo da imagem para manter os aplicativos contidos em container. De forma simples podemos dizer que ConfigMap é um conjunto de pares de chave-valor para armazenamento de configurações, que ficará armazenado dentro de arquivos que podem ser consumidos através de Pods ou Controllers,. Ele é muito parecido com Secrets, mas fornece um modo de se trabalhar com strings que não possuem dados confidências, como senhas, Chaves, Tokens e outros dados sigilosos.
Os arquivos de ConfigMap, podem ser tanto arquivos complexos que possuem poucas regras, como também arquivos no formato JSON complexos e cheio de regras. Podemos ver alguns exemplos abaixo de ConfigMaps tanto simples quanto complexos: Podemos ver aqui um exemplo de criação de um ConfigMap através do client do Kubernetes “kubectl”
kubectl create configmap site --from-literal='url=mundodocker.com.br' Podemos ver
Podemos ver aqui um outro exemplo que é um arquivo de configuração que a partir dele também podemos criar o nosso ConfigMap
Como foi visto acima existe 2 formas nas quais podemos criar o nosso ConfigMap, mas ahhh Bicca, como integramos isso com nosso Pod? Existem algumas formas para isso a primeira é que você pode colocar isso dentro do arquivo de criação do Pod, como mostro abaixo:
Essa seria a forma de criação de um Pod com ConfigMap habilitado por exemplo, esses são exemplos simples de arquivos que mostram como funciona o uso de ConfigMaps.
ALGUMAS DICAS:
Lembre-se que para que seja possível criar o seu Pod com ConfigMap, você precisa primeiro criar o ConfigMap ou coloca-lo como opcional, pois caso contrario o Pod não irá ser iniciado por causa que o ConfigMap ainda não foi criado.
ConfigMap estão dentro de Namespaces, então apenas Pods do mesmo Namespace podem acessa-los
Podem ser consumidos de 3 formas: Argumentos, Variaveis de ambiente e Arquivos em volumes. Essa quantidade de modos faz com que ConfigMap se enquadre em grandes partes das aplicações.
Pessoal, vamos continuar criando posts para explicar alguns componentes do Kubernetes e em breve vamos colocar mais conteúdos para demonstrar como é possível utilizar Kubernetes em produção com exemplos de uso no dia-a-dia, fique ligado que em breve estaremos com muitas novidades em nosso site e também.
Trabalha em uma consultoria com foco em Plataforma como Serviço (PaaS), é especialista em Cloud Computing e Conteinerização, desenvolve todo dia uma nova maneira de resolver problemas e criar coisas novas.
Conforme falamos em um post anterior o Docker lançou uma nova versão a 1.13 e nessa nova versão tivemos diversas melhorias e com a entrada dessa nossa versão também tivemos a criação de uma nova versão no Docker Compose que é a v3. Essa nova versão é totalmente compatível com o Docker Swarm que hoje é nativo na mesma engine no Docker, então agora com Docker Compose podemos gerenciar nossos serviços através do Docker Swarm.
Agora com a V3 existe opção chamada deploy que é responsável por realizar as implantações e execução de serviços. Dentro dessa opção temos as seguintes funções:
Mode
Onde é possível escolher a opção “Global” (Um container por nó de swarm) ou “Replicated” (Onde posso escolher a quantidade de réplicas que estarão distribuídas entre os nós). O padrão é replicated.
Replicas
replicas: x
Global
Placement
Especifica restrições de posicionamento são elas:
node.id = idworker
node.hostname = nomeworker
node.role = manager ou worker
node.lables = nome
engine.labels = Sistema Operacional ou Driver
Update_config
Configura como devem ser as opções de atualizações dos serviços.
Parallelism: 5 #O Numero de containers que vão ser atualizados em paralelo.
delay: 10s #O tempo entre cada grupo de containers será atualizado
failure_action: pause ou continue #O que irá acontecer se a atualização falhar. O padrão é pause.
monitor: 0s # Duração após cada atualização para monitorar a falha. O padrão é 0s.
max_failure_ratio: #Taxa de falha para atualizar.
resources
Configura a restrição de recursos
limits:
cpus: ‘0.5’ # 0.5 representa 50% de um núcleo, porem pode ser 1 ou 1.5 ou 2….
memory: ‘512M’ #apenas especificar o prefixo M, G, K….
Restart_policy
Configura como reiniciar os containers quando eles derem exit.
condity: none on-failure any #Por padrão é any
delay: 0s #Tempo entre as tentativas de reiniciar o containers #Por padrão é 0s
max_attempts: 0 #Quantas vezes irá tentar subir o container antes de desistir #Por padrão é nunca desistir.
window: 0s #Quanto tempo demora para decidir se um reinicio foi bem sucedido #Por padrão é imediatamente,
Alem dessas opções, com a entrada da V3 foram descontinuadas as seguintes opções do Docker Compose: volume_driver, volumes_from, cpu_shares, cpu_quota, cpuset, mem_limit, memswap_limit
Agora vamos demonstrar um exemplo de como ficaria o docker-compose.yml com essas opções que mostramos acima.
Executando o comando docker deploy --compose-file docker-compose.yml nomedastack criamos a stack mencionada acima em nossa estrutura. Após executar esse comando é possível dar um docker stack ls e você poderá ver que a sua stack foi criada, com o nome da sua stack você pode executar o docker stack services nomedastack e poderá ver os serviços criados e qual o seu status.
Então ta pessoal, por hoje era isso, espero que tenham gostado e qualquer dúvida é só deixar um comentário que estaremos felizes em lhe ajudar, nos ajude divulgando o blog obrigado!
Trabalha em uma consultoria com foco em Plataforma como Serviço (PaaS), é especialista em Cloud Computing e Conteinerização, desenvolve todo dia uma nova maneira de resolver problemas e criar coisas novas.
Hoje o post é rápido, apenas para trazer a vocês nossa experiência no TcheLinux Caxias do Sul. Para quem nos acompanha nas rede sociais, ficou sabendo que iriamos participar de mais um edição do TcheLinux (um dos maiores eventos de tecnologia open source do Rio Grande do Sul), dessa vez em Caxias do Sul, na serra gaúcha. O evento estava muito bem organizado, e o lugar não poderia ser melhor, com infraestrutura suficiente para atender os participantes, sem falar na localização. Com a ajuda de alguns amigos, conseguimos alguns registro fotográficos do evento, veja:
A nossa contribuição ao evento foi com uma palestra: Escalonando o mundo com Kubernetes, como o Google sobrevive. Essa apresentação teve como objetivo mostrar aos presentes como o Kubernetes funciona, como ele é utilizado dentro do Google e como você utiliza ele sem nem saber 🙂 . Compartilhamos a apresentação em nosso Slideshare, para você, que não estava no evento, possa ver um pouco sobre o que levamos ao evento:
Gostaríamos de agradecer ao TcheLinux pela oportunidade e a Ftec que disponibilizou o local para o evento. Por hoje era isso, grande abraço! Ahhh e nos ajude divulgando o blog 😉
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.
Hoje, você não pode pensar em utilizar Docker em produção em larga escala sem ter alguma forma de automação e orquestração dessa “coisa”, graças a comunidade e algumas empresas, temos ferramentas que podem nos auxiliar nessas tarefas, todas juntas ou em partes, é claro. Atualmente as ferramentas mais conhecidas para orquestração e scale em Docker são Kubernetes e Mesos, existem muitos projetos mantidos pela comunidade nesse sentido, mas nenhum deles com tanta representatividade quanto aos mencionados anteriormente. Para não ficar de fora desse mundo, a Docker vem trabalhando bastante em uma suite que atenda essa necessidade, e que futuramente seja incorporado ao Docker Data Center, o projeto chama-se Swarmkit, e hoje, aqui no MundoDocker, vamos ver um pouco mais sobre ele.
O Que é?
O Swarmkit é uma suite para escalonamento e orquestração para sistemas distribuídos, ele possui um sistema de descoberta de nós, agendamento de tarefas, e utiliza o raft-based consensus para coordenação do cluster.
O que tem de bom?
Como já mencionado, ele utiliza o raft-based consensus, isso garante uma melhor coordenação do cluster, eliminando assim o ponto único de falha.
Todo os nós do cluster Swarm conversam de forma segura, e para ajudar nisso o Swarmkit utiliza TLS para autenticação, autorização e transporte dos dados entre os nós.
Swarmkit foi projeto para ser simples, por isso ele é independente de base de dados externas, ou seja, tudo que você precisa para utiliza-lo já está nele.
Ele é composto basicamente de duas camadas: Worker e Manager nodes, para entender cada um:
Worker: Responsável por executar as tarefas utilizar um Executor, por padrão o Swarmkit vem com o Docker Container Executor, mas que pode ser trocado caso deseja.
Manager: Basicamente é o nó eleito pelo administrador para ser o ponto central de administração, lembrando que quanto você adiciona um nó no cluster de Swarm você define se esse nó será Manager ou não.
Como outras ferramentas, para o Swarmkit as tarefas são organizadas em serviços, e para esse serviço você define o que deseja fazer, por exemplo: Crie replicas desse serviço todo dia as 10h, ou: Atualize um container por vez baseado nessa nova imagem.
Features
Oquestração
Estado desejado: O Swarmkit analise constantemente o cluster, garantindo que todos os serviços estejam de acordo com o pretendido pelo usuário, isso faz com que um serviço seja provisionado em outro nó caso algum falhe.
Tipo de serviço: atualmente o Swarmkit suporta apenas 2 tipos: 1 – Replicas, onde você define quantas cópias daquele container deseja, e 2 – Global, onde você especifica o que deve ser executado em cada nó do cluster.
Atualização: Você pode modificar a qualquer momento o estado de um serviço, seja para para-lo ou escala-lo, quando você atualiza um serviço, por padrão ele executa essa tarefa de atualização de uma vez só para todos os nós do cluster, mas você pode definir de outras duas formas essa atualização: 1 – Paralela, onde o administrador define quantas tarefas de atualização podem ser executadas por mês ou 2 – Delay, dessa forma o Swarmkit executará as tarefas de atualização de serviço de forma sequencial, ou seja, uma tarefa só será executada caso a anterior já tenha terminado.
Politicas de restart: A camada de orquestração monitora o estado das tarefas e reage as falhas aplicando a regra definida pelo usuário, dentro dessas regras o administrador pode definir número máximo de tentativos de restart de um serviço, quanto tempo depois de uma falha esse serviço deve ser reiniciado, etc. Por padrão o Swarmkit reinicia o serviço dentro de outro nó disponível no cluster, isso garante que os serviços dos nós defeituosos sejam iniciados em outros nós o mais rápido possível.
Agendamento
Recursos: O Swarmkit sabe, através das checagens constantes, como está a saúde de cada nó, com isso, quando um serviço precisa ser reiniciado ou realocado, por padrão essa tarefa será realizada no melhor nó do cluster;
Restrições: O administrador pode limitar o reinicio de um serviço em determinados nós, isso pode ser feito através de labels, exemplo: node.labels.foo!=bar1
Gerenciamento de cluster
State Store: Permite ter uma visão macro de todo o cluster, como suas informações ficam em memória, permite ao nó de gerenciamento tomar decisões de forma muito mais rápida e segura.
Gerenciamento da topologia: O administrador pode alternar quais são os nós de gerenciamento e qual são os Workers através de chamadas de API ou CLI.
Gerenciamento de nós: É possível definir um nó como pausado, por exemplo, com isso os serviços que estavam alocados neste nó serão iniciados nos demais nós, assim como a execução de novas tarefas permanece bloqueada.
Segurança
TLS: Todos os nós se conversam através de TLS, e os nós de gerenciamento agem como autoridade certificadora de todos os demais nós, e são responsáveis pela emissão de certificados para os nós que entram no cluster.
Politica de aceitação: O administrador pode aplicar regras de auto-aceitação, aceitação manual ou troca de chaves, isso claro na adição de novos nós ao cluster, por default o Swarmkit utiliza auto-aceitação.
Troca de certificados: É possível definir a frequência com a qual serão alterados os certificados ssl utilizados para comunicação do cluster, por padrão o tempo é de 3 meses, mas pode-ser definir qualquer período maior que 30 minutos.
Vamos brincar?
Instalando
O Swarmkit foi desenvolvido em GO, então tenha todo o ambiente pré-configurado e claro, baixe os fontes para seu $GOPATH, você pode utilizar:
[root@docker1 ~]# go get github.com/docker/swarmkit/
Acesse o diretório, e execute:
[root@docker1 ~]# make binaries
Isso fará com que sejam instaladas as ferramentas para utilização do Swarmkit, em seguida você pode testar sua instalação:
[root@docker1 ~]# make setup
[root@docker1 ~]# make all
Agora adicione o swarmd e swarmctl ao seu $PATH e seja feliz utilizando ele, veja abaixo alguns exemplos.
Você pode agora, utilizar outro host para administrar o cluster, no nosso exemplo utilizando o docker4, veja:
[root@docker4 ~]# export SWARM_SOCKET=/tmp/manager1/swarm.sock
[root@docker4 ~]# swarmctl node ls
ID Name Membership Status Availability Manager status
-- ---- ---------- ------ ------------ --------------
6rj5b1zx4makm docker1 ACCEPTED READY ACTIVE REACHABLE *
91c04eb0s86k8 docker2 ACCEPTED READY ACTIVE
nf6xx9hpf3s39 docker3 ACCEPTED READY ACTIVE
Criando os serviços
Vamos começar devagar, veja como subir um ambiente em redis:
[root@docker4 ~]# swarmctl service create --name redis --image redis:3.0.5
6umyydpxwtzfs3ksgz0e
Listando os serviços:
[root@docker4 ~]# swarmctl service ls
ID Name Image Replicas
-- ---- ----- ---------
6umyydpxwtzfs3ksgz0e redis redis:3.0.5 1
Inspecionando o serviço:
[root@docker4 ~]# swarmctl service inspect redis
ID : 6umyydpxwtzfs3ksgz0e
Name : redis
Replicass : 1
Template
Container
Image : redis:3.0.5
Task ID Service Instance Image Desired State Last State Node
------- ------- -------- ----- ------------- ---------- ----
6umyydpxwtzfs3ksgz0e redis 1 redis:3.0.5 RUNNING RUNNING Up About an hour docker1
Atualizando serviço:
Conforme mencionado anteriormente, podemos atualizar o status de um serviço, no nosso exemplo vamos aumentar o número de replicas dele, veja:
[root@docker4 ~]# swarmctl service update redis --replicas 6
6umyydpxwtzfs3ksgz0e
[root@docker4 ~]# swarmctl service inspect redis
ID : 6umyydpxwtzfs3ksgz0e
Name : redis
Replicas : 6
Template
Container
Image : redis:3.0.5
Task ID Service Instance Image Desired State Last State Node
------- ------- -------- ----- ------------- ---------- ----
xaoyxbuwe13gsx9vbq4f redis 1 redis:3.0.5 RUNNING RUNNING Up About an hour docker1
y8cu8nvl1ggh4sl0xxs4 redis 2 redis:3.0.5 RUNNING RUNNING 10 seconds ago docker2
ksv9qbqc9wthkrfz0jak redis 3 redis:3.0.5 RUNNING RUNNING 10 seconds ago docker2
nnm9deh7t0op6rln3fwf redis 4 redis:3.0.5 RUNNING RUNNING 10 seconds ago docker1
4ya5eujwsuc6cr7xlnff redis 5 redis:3.0.5 RUNNING RUNNING 10 seconds ago docker3
9o4pmrz6q6pf9ufm59mk redis 6 redis:3.0.5 RUNNING RUNNING 10 seconds ago docker3
Vamos atualizar a imagem do serviço?
[root@docker4 ~]# swarmctl service update redis --image redis:3.0.6
6umyydpxwtzfs3ksgz0e
[root@docker4 ~]# swarmctl service inspect redis
ID : 6umyydpxwtzfs3ksgz0e
Name : redis
Replicas : 6
Template
Container
Image : redis:3.0.6
Task ID Service Instance Image Desired State Last State Node
------- ------- -------- ----- ------------- ---------- ----
xaoyxbuwe13gsx9vbq4f redis 1 redis:3.0.6 RUNNING RUNNING 5 seconds ago docker3
y8cu8nvl1ggh4sl0xxs4 redis 2 redis:3.0.6 RUNNING RUNNING 6 seconds ago docker1
ksv9qbqc9wthkrfz0jak redis 3 redis:3.0.6 RUNNING RUNNING 5 seconds ago docker2
nnm9deh7t0op6rln3fwf redis 4 redis:3.0.6 RUNNING RUNNING 6 seconds ago docker1
4ya5eujwsuc6cr7xlnff redis 5 redis:3.0.6 RUNNING RUNNING 6 seconds ago docker2
9o4pmrz6q6pf9ufm59mk redis 6 redis:3.0.6 RUNNING RUNNING 6 seconds ago docker3
Por padrão todos os containers foram atualizados de uma única vez, isso tem suas vantagens e desvantagens, mas como explicado, você pode mudar essa execução para fazer em partes, veja:
Com isso, serão refeitos 3 containers por vez e entre eles terá um intervalo de 20 segundos.
Gerenciando nós
O Swarmkit monitora a saúde de cluster, e baseado nisso toma ações em cima dos serviços, você pode realizar ações manuais também, como por exemplo, retirar um nós do cluster, veja:
[root@docker4 ~]# swarmctl node drain docker1
[root@docker4 ~]# swarmctl node ls
ID Name Membership Status Availability Manager status
-- ---- ---------- ------ ------------ --------------
6rj5b1zx4makm docker1 ACCEPTED READY DRAIN REACHABLE
91c04eb0s86k8 docker2 ACCEPTED READY ACTIVE REACHABLE *
nf6xx9hpf3s39 docker3 ACCEPTED READY ACTIVE REACHABLE
[root@docker4 ~]# swarmctl service inspect redis
ID : 6umyydpxwtzfs3ksgz0e
Name : redis
Replicas : 6
Template
Container
Image : redis:3.0.7
Task ID Service Instance Image Desired State Last State Node
------- ------- -------- ----- ------------- ---------- ----
xaoyxbuwe13gsx9vbq4f redis 1 redis:3.0.7 RUNNING RUNNING 2 minute ago docker2
y8cu8nvl1ggh4sl0xxs4 redis 2 redis:3.0.7 RUNNING RUNNING 2 minute ago docker3
ksv9qbqc9wthkrfz0jak redis 3 redis:3.0.7 RUNNING RUNNING 30 seconds ago docker2
nnm9deh7t0op6rln3fwf redis 4 redis:3.0.7 RUNNING RUNNING 34 seconds ago docker3
4ya5eujwsuc6cr7xlnff redis 5 redis:3.0.7 RUNNING RUNNING 28 minutes ago docker2
9o4pmrz6q6pf9ufm59mk redis 6 redis:3.0.7 RUNNING RUNNING 29 seconds ago docker3
O Swarmkit é uma ferramenta em desenvolvimento ainda, mas você pode utilizar ela em seus labs e entender um pouco melhor como pode trabalhar em cluster com Docker. Espero que tenham gostado, e nos ajude divulgando o blog 😉
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.