Oi Gente!!
Iniciando 2019 e esse ano promete mudanças, em todos os aspectos, aqui no Blog também ;), esperamos que esse ano seja de grandes realizações, para todos nós.
Então, se você já trabalha com Docker, já deve ter passado por alguma situação onde as regras de iptables não são obedecidas, é, isso acontece :(.
Se você ainda não mexeu com Docker, recomendo este post aqui, que explica um pouco sobre o que é o Docker e como ele funciona, e te prepara pois o que mostraremos no post de hoje será bem útil para você.
O problema
Por padrão o Docker manipula regras no iptables, mas, por que ele faz isso? Porque quando você cria um container o Docker precisa criar algumas regras para encaminhamento de tráfego, isolamento, etc. É possível desabilitar esse comportamento, porém, você precisará garantir isso manualmente 🙂
Digamos que você tem seu iptables bonito, nele você libera apenas a porta 80 e 22, e bloqueia todo o resto, para isso é provável que você utilize as seguintes regras:
iptables -P INPUT DROP
iptables -A INPUT --dport 80 -j ACCEPT
iptables -A INPUT --dport 22 -j ACCEPT
Neste servidor você tem Docker rodando, e criou um container na porta 80 obviamente para responder as requisições que são feitas.
Ok, agora você teve a necessidade de criar outra container, este em outra porta, e neste container você terá o ambiente de homologação, como você já tem um container executando e utilizando a porta 80, você precisará criar na porta 8080, ok, sem problema, agora posso ir no meu iptables e liberar a porta 8080 APENAS para o meu ip, óbvio que funciona:
iptables -A INPUT -s 10.1.1.2 --dport 8080 -j ACCEPT
Não, não funciona. E a explicação para esse comportamento encontramos em um dos assuntos primordiais da existência de um Sysadmin Linux, o comportamento do iptables.
Para recapitularmos, o iptables é basicamente é um interpretador de regras gerando ações baseadas nessas regras. Dentro do iptables temos três tabelas, são elas: Filter, Nat e Mangle. A tabela mais utiliza de todas é a Filter, é nessa tabela que criamos nossas regras para bloqueio de portas/ips. Dentro dessa tabela encontramos outras três chains, são elas:
- INPUT: Consultado para pacotes que chegam na própria máquina;
- FORWARD: Consultado para pacotes que são redirecionados para outra interface de rede ou outra estação. Utilizada em mascaramento.
- OUTPUT: Consultado para pacotes que saem da própria máquina;
Agora advinha em qual chain são criadas as regras do Docker? Sim, em uma chain de forward, isso por que o pacote não é destinado para o host e sim para a interface que o Docker cria. É importante saber disso, pois o fluxo dentro do iptables muda se o destino do pacote é local ou não.
Para ficar mais claro, dá uma olhada nessa imagem: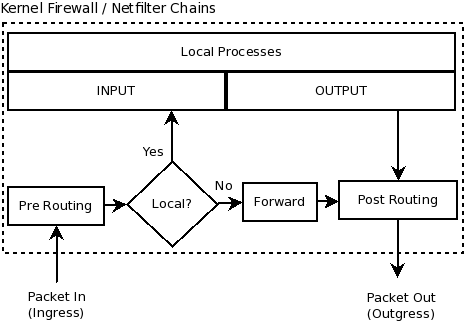 Isso quer dizer que aquele seu container que foi criado na porta 8080 ficará exposto, pois a regra de forward será executada antes daquela sua regra de input que bloqueia tudo ;). A chain utilizada neste caso chama-se DOCKER, e você pode visulizar as regras criadas utilizando o:
Isso quer dizer que aquele seu container que foi criado na porta 8080 ficará exposto, pois a regra de forward será executada antes daquela sua regra de input que bloqueia tudo ;). A chain utilizada neste caso chama-se DOCKER, e você pode visulizar as regras criadas utilizando o:
iptables -L -nv
“Oh, e agora quem poderá nos defender?”
A Solução
Até pouco tempo atrás havia basicamente uma solução, nem um pouco “elegante” de se resolver isso.
- Desabilitar no daemon do Docker para ele não manipular de forma automatica essas regras, com isso você precisaria criar manualmente as regras;
Existiam outras formas? Sim, algumas mais complexas, outras mais baixo nível, mas de qualquer forma nada tão simples e muito menos fácil de se administrar, então, depois de vários pedidos e sugestões de solução no github do Docker, isso foi repensado e resolvido de uma forma mais inteligente.
Foi adicionado uma nova Chain, chamada DOCKER-USER, essa chain apesar de ser forward também, precede as chains utilizadas pelo Docker na criação de containers. Dessa forma, você pode utilizar ela para adicionar as suas regras personalizadas e garantir o bloqueio ou acesso aos containers.
Te lembra daquelas regra que não funcionava antes? Então, neste novo cenário, ficará dessa forma:
iptables -I DOCKER-USER -s 10.1.1.2 --dport 8080 -j ACCEPT
iptables -A DOCKER-USER --dport 8080 -j DROP
Bem mais simples do que manipular todas as regras do Docker manualmente, certo? Mas lembre-se, isso serve apenas para controlar o trafego externo aos containers, isso não é aplicado no contexto de INPUT, então tome cuidado achando que é nessa chain que deve ir todas as suas regras. Outro ponto positivo para essa abordagem é a simplicidade para automatizar, pois basta integrar essa mesma lógica em sua pipeline e você estará protegendo seus containers.
É possível ainda manter aquele seu script maroto de firewall, basta adicionar mais algumas regras liberando ou não o acesso a determinada porta (na qual quem responderá será um container).
Então era isso, se quiser saber mais, tirar alguma dúvida ou ainda ajudar, deixa ai nos comentários ou entre em contato por e-mail. Grande abraço e boa semana 😉

Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.