
Post incialmente públicado em: https://dumpscerebrais.com/2019/01/migrando-do-docker-swarm-para-o-kubernetes
Começamos 2019 e ficou bem claro que o Docker Swarm perdeu para o Kubernetes na guerra de orquestradores de contêineres.
Não vamos discutir aqui motivos, menos ainda se um é melhor que outro. Cada um tem um cenário ótimo para ser empregado como já disse em algumas das minhas palestras sobre o assunto. Mas de uma maneira geral se considerarmos o requisito evolução e compararmos as duas plataformas então digo que se for construir e manter um cluster de contêineres é melhor já começarmos esse cluster usando Kubernetes.
O real objetivo desse artigo é mostrar uma das possíveis abordagens para que nossas aplicações hoje rodando num cluster Docker Swarm, definidas e configuradas usando o arquivo docker-compose.yml possam ser entregues também em um cluster Kubernetes.
Intro
Já é meio comum a comparação entre ambos e posso até vir a escrever algo por aqui mas no momento vamos nos ater a um detalhe simples: cada orquestrador de contêineres cria recursos próprios para garantir uma aplicação rodando. E apesar de em alguns orquestradores recursos terem o mesmo nome, como o Services do Docker Swarm e o Services do Kubernetes eles geralmente fazem coisas diferente, vem de conceitos diferentes, são responsáveis por entidades diferentes e tem objetivos diferentes.
O Kompose, uma alternativa
O kompose é uma ferramenta que ajuda muito a converter arquivos que descrevem recursos do Docker em arquivos que descrevem recursos do Kubernetes e até dá para utilizar diretamente os arquivos do Docker Compose para gerir recursos no Kubernetes. Também tenho vontade de escrever sobre ele, talvez em breve, já que neste artigo vou focar em como ter recursos do Docker Swarm e do Kubernetes juntos.
Um pouco de história
Sempre gosto de passar o contexto para as pessoas entenderem como, quando e onde foram feitas as coisas, assim podemos compreender as decisões antes de pré-julgarmos.
Na Dockercon européia de 2017, a primeira sem o fundador Solomon Hykes, foi anunciado e demostrado como usar um arquivo docker-compose.yml para rodar aplicações tanto num cluster Docker Swarm quanto num cluster Kubernetes usando a diretiva Stacks.
A demostração tanto na Dockercon quanto no vídeo acima foram sensacionais. Ver que com o mesmo comando poderíamos criar recursos tanto no Docker Swarm quanto no Kubernetes foi um marco na época. O comando na época:
docker stack deploy --compose-file=docker-compose.yml stackname
Só tinha um problema, isso funcionava apenas em instalações do Docker Enterprise Edition ($$$) ou nas novas versões do Docker for Desktop que eram disponíveis apenas para OSX e Windows.
Aí você pergunta: Como ficaram os usuário de Linux nessa história, Wsilva?
Putos, eu diria.
Protecionismo?
Assim como outros também tentei fazer uma engenharia reversa e vi que o bootstrap desse Kubernetes rodando dentro do Docker for Mac e Windows era configurado usando o Kubeadm. Fucei, criei os arquivos para subir os recursos Kubernetes necessários e quase consegui fazer rodar mas ainda me faltava descobrir como executar o binário responsável por extender a api do Kubernetes com os parâmetros certos durante a configuração de um novo cluster, todas as vezes que rodei tive problemas diferentes.
Até postei um tweet a respeito marcando a Docker Inc mas a resposta que tive foi a que esperava: a Docker não tem planos para colocar suporte ao Compose no Linux, somente Docker for Desktop e Enterprise Edition.
Ainda bem antes de tentar fazer isso na mão, lá na Dockercon de 2018 (provavelmente também escreverei sobre ela) tive a oportunidade de ver algumas palestras sobre extender a API do Kubernetes, sobre como usaram Custom Resource Definition na época para fazer a mágica de interfacear o comando docker stack antes de mandar a carga para a API do Kubernetes ou para a API do Docker Swarm e também conversei com algumas pessoas no conference a respeito.
A desculpa na época para não termos isso no Docker CE no Linux era uma questão técnica, a implementação dependeria muito de como o Kubernetes foi instalado por isso que no Docker para Desktop e no Docker Enterprise, ambientes controlados, essa bruxaria era possível, mas nas diversas distribuíções combinadas com as diversas maneiras de criar um cluster Kubernetes seria impossível prever e fazer um bootstrap comum a todos.
Docker ainda pensando no Open Source?
Na Dockercon européia de 2018, praticamente um ano depois do lançamento do Kubernetes junto com o Swarm finalmente foi liberado como fazer a API do Compose funcionar em qualquer instalação de Kubernetes. Mesmo sem as instruções de uso ainda mas já com os fontes do instalador disponíveis (https://github.com/docker/compose-on-kubernetes) era possível ver que a estrutura tinha mudado de Custom Resource Definition para uma API agregada e relativamente fácil de rodar em qualquer cluster Kubernetes como veremos a seguir.
Mão na massa.
Para rodarmos essa API do Compose no Mac e no Windows, assim como no final de 2017, basta habilitar a opção Kubernetes na configuração conforme a figura e toda a mágica vai acontecer.
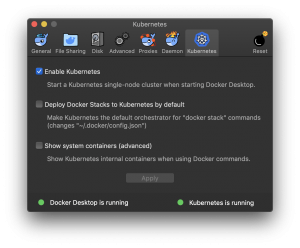
No Linux podemos trabalhar com o Docker Enterprise Edition ou com o Docker Community Edition.
Para funcinar com o Docker Community Edition primeiramente precisamos de um cluster pronto rodando kubernetes e podemos fazer teoricamente em qualquer tipo de cluster. Desde clusters criados para produção com Kops – (esse testei na AWS e funcionou), ou Kubespray, ou em clusteres locais como esse que criei para fins educativos: https://github.com/wsilva/kubernetes-vagrant/ (também funcionou), ou Minikube (também funcionou, está no final do post), ou até no saudoso play with kubernetes (também funcionou) criado pelo nosso amigo argentino Marcos Nils.
Para verificar se nosso cluster já não está rodando podemos checar os endpoints disponíveis filtrando pela palavra compose:
$ kubectl api-versions | grep compose
Pré requisitos
Para instalar a api do Compose em um cluster Kubernetes precisamos do etcd operator rodando e existem maneiras de instalar com e sem suporte a SSL. Mais informações podem ser obtidas nesse repositório.
Neste exemplo vamos utilizar o gerenciador de pacotes Helm para instalar o etcd operator.
Instalação
Primeiro criamos o namespace compose em nosso Kubernetes:
$ kubectl create namespace compose
Em seguida instalmos ou atualizamos o Helm.
Se estivermos utilizando OSX, podemos instalar de maneira simples com homebrew.
$ brew install kubernetes-helm
Updating Homebrew...
Error: kubernetes-helm 2.11.0 is already installed
To upgrade to 2.12.3, run `brew upgrade kubernetes-helm`
$ brew upgrade kubernetes-helm
Updating Homebrew...
==> Upgrading 1 outdated package:
kubernetes-helm 2.11.0 -> 2.12.3
==> Upgrading kubernetes-helm
==> Downloading https://homebrew.bintray.com/bottles/kubernetes-helm-2.12.3.moja
######################################################################## 100.0%
==> Pouring kubernetes-helm-2.12.3.mojave.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completions have been installed to:
/usr/local/share/zsh/site-functions
==> Summary
? /usr/local/Cellar/kubernetes-helm/2.12.3: 51 files, 79.5MB
No Linux podemos optar por gerenciadores de pacotes ou instalar manualmente baixando o pacote e colocando em algum diretório do PATH:
$ curl -sSL https://storage.googleapis.com/kubernetes-helm/helm-v2.12.1-linux-amd64.tar.gz -o helm-v2.12.1-linux-amd64.tar.gz
$ tar -zxvf helm-v2.12.1-linux-amd64.tar.gz
x linux-amd64/
x linux-amd64/tiller
x linux-amd64/helm
x linux-amd64/LICENSE
x linux-amd64/README.md
$ cp linux-amd64/tiller /usr/local/bin/tiller
$ cp linux-amd64/helm /usr/local/bin/helm
Estamos em 2019 então todos os clusters Kubernetes já deveriam estar rodando com RBAC (Role Base Access Control) por questões de segurança. Para isso devemos criar uma Service Account em nosso cluster para o tiller.
$ kubectl --namespace=kube-system create serviceaccount tiller
serviceaccount/tiller created
$ kubectl --namespace=kube-system \
create clusterrolebinding tiller \
--clusterrole=cluster-admin \
--serviceaccount=kube-system:tiller
clusterrolebinding.rbac.authorization.k8s.io/tiller created
Neste exemplo fizemos o bind para o role cluster admin, mas seria interessante criar uma role com permissões mais restritas definindo melhor o que o helm pode ou não fazer em nosso cluster Kubernetes.
Instalamos o etcd operator:
$ helm init --service-account tiller --upgrade
$ helm install --name etcd-operator \
stable/etcd-operator \
--namespace compose
Monitoramos até os pods responsáveis pelo etcd operator estarem de pé:
$ watch kubectl get pod --namespace compose
Com etcd operator de pé podemos matar o watch loop com ctrl+c.
Próximo passo vai ser subir um cluster etcd usando o operator:
$ cat > compose-etcd.yaml <<EOF
apiVersion: "etcd.database.coreos.com/v1beta2"
kind: "EtcdCluster"
metadata:
name: "compose-etcd"
namespace: "compose"
spec:
size: 3
version: "3.2.13"
EOF
$ kubectl apply -f compose-etcd.yaml
Monitoramos novamente até os pods responsáveis pelo nosso etcd cluster estarem de pé:
$ watch kubectl get pod --namespace compose
Com etcd cluster rodando podemos matar o watch loop com ctrl+c.
Em seguida baixamos diretamente do GitHub e executamos o instalador da API do Compose.
Se estivermos utilizando OSX:
$ curl -sSLO https://github.com/docker/compose-on-kubernetes/releases/download/v0.4.18/installer-darwin
chmod +x installer-darwin
./installer-darwin \
-namespace=compose \
-etcd-servers=http://compose-etcd-client:2379 \
-tag=v0.4.18
No Linux:
$ curl -sSLO https://github.com/docker/compose-on-kubernetes/releases/download/v0.4.18/installer-linux
chmod +x installer-linux
./installer-linux \
-namespace=compose \
-etcd-servers=http://compose-etcd-client:2379 \
-tag=v0.4.18
Vamos checar se os pods estão rodando novamente com watch loop:
watch kubectl get pod --namespace compose
Após todos os pods rodando usamos o ctrl+c para parar o watch loop e em seguida podemos verificar se agora temos os endpoints do compose:
$ kubectl api-versions | grep compose
compose.docker.com/v1beta1
compose.docker.com/v1beta2
Sucesso. Agora vamos baixar um arquivo docker compose de exemplo do repositório da própria Docker:
curl -sSLO https://github.com/docker/compose-on-kubernetes/blob/master/samples/docker-compose.yml
Para ver o conteudo do arquivo podemos usar um editor de texto ou o simples cat docker-compose.yml no terminal mesmo.
Agora vamos usar o docker para criar os recursos no kubernetes, como se estivessemos fazendo um deployment em um cluster de Docker Swarm mesmo:
$ docker stack deploy \
--orchestrator=kubernetes \
--compose-file docker-compose.yml \
minha-stack
Podemos usar tando o kubectl como o docker cli para checar os status:
$ kubectl get stacks
NAME SERVICES PORTS STATUS CREATED AT
demo-stack 3 web: 80 Available (Stack is started) 2019-01-28T20:47:38Z
$ docker stack ls \
--orchestrator=kubernetes
NAME SERVICES ORCHESTRATOR NAMESPACE
demo-stack 3 Kubernetes default
Podemos pegar o ip da máquina virtual rodando minikube com o comando minikube ip e a porta do serviço web-published e acessar no nosso navegador.
No próprio repositório temos uma matriz de compatibilidade entre as funcionalidades no Docker Swarm e funcionalidades no Kubernetes: https://github.com/docker/compose-on-kubernetes/blob/master/docs/compatibility.md
Conclusão
Se você está pensando em migrar seus workloads de clusters de Docker Swarm para clusters de Kubernetes você pode optar tanto pelo Kompose quanto pelo Docker Compose no Kubernetes.
Optando pelo Compose no Kubernetes podemos usar o Docker for Mac ou Docker for Windows, basta habilitar nas configurações a opção de cluster Kubernetes.
Se estiver no Linux pode optar por seguir os passos acima ou pagar pelo Docker Enterprise Edition.
Veja como cada uma dessas opções se adequa melhor aos seus processos e divirta-se.
Até a próxima.

Conhecido como Boina, Tom e Wsilva entre outros apelidos. Possui certificações Docker Certified Associate e ZCE PHP 5.3, autor do livro Aprendendo Docker, do básico à orquestração de contêineres publicado pela editora Novatec. Docker Community Leader em São Paulo, tem background em telecomunicações, programação, VoIP, Linux e infraestrutura.








