Opa!
Acreditamos que um dos maiores desafios quando se trabalha com alguma tecnologia de cluster, é a forma como você vai disponibilizar o conteúdo para seu usuário/cliente, obviamente isso pode ser feito de diversas maneiras, e cada uma delas atender a uma necessidade e objetivo.
A intenção hoje é trazer à vocês uma forma simples de se disponibilizar conteúdo web (site, api, etc.) e que tem como backend o Docker Swarm, sim, hoje falaremos do Traefik, um poderoso proxy web dinâmico. Antes disso, temos que responder a seguinte dúvida: Por que diabos preciso de um proxy reverso dinâmico? Simples, por que as implementações atuais de Apache, Haproxy e Nginx foram desenvolvidas para serem estáticos, necessitando de intervenções para que as modificações sejam aplicadas. É claro que existem iniciativas que tratam isso, e são boas alternativas também, como é o caso do docker-flow-proxy e jwilder/nginx mas são presas ao que as tecnologias base oferecerem. No caso do traefik, a situação é bem diferente, ele é um proxy arquitetado e desenvolvimento para ser totalmente dinâmico e orientado a micro-serviços, além disso, ele suporta nativamente diversos tipos de backend, como é o caso do Docker Swarm, Kubernetes, Mesos, Docker apenas, Consul, dentre muitos outros.
Features
Algumas features/benefícios do Traefik, incluem:
- Veloz.
- Sem dependência, ele é um binário escrito em go.
- Existe imagem oficial para Docker.
- Fornece uma API Rest.
- Reconfiguração sem a necessidade de reiniciar o processo.
- Metricas (Rest, Prometheus, Datadog, Statd).
- Web UI em AngularJS.
- Suporte a Let’s Encrypt (Com renovação automática).
- Alta disponibilidade em modo cluster (beta).
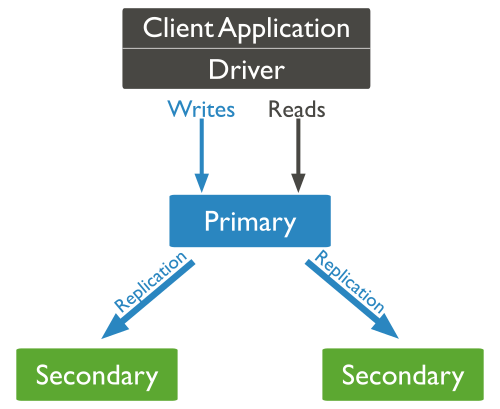
O Traefik foi desenvolvido para atender a demanda de requisições web, então ele pode ser utilizado para fazer o roteamento das conexões de um site ou api para o container ou serviço que foi criada para isso. A imagem abaixo é clássica, e explica bem esse comportamento:

Fonte: https://docs.traefik.io
Como pode ser visto, o traefik fica “ouvindo” as ações que ocorrem no orquestrador (independente de qual for) e baseado nessa ações se reconfigura para garantir o acesso ao serviço/container criado. Dessa forma basta você apontar as requisições web (seja http ou https) para o servidor onde o traefik está trabalhando.
Mãos a massa?
Em nosso lab, vamos montar esse ambiente utilizando o Docker Swarm como nosso orquestrador, para isso, tenha pelo menos três hosts, inicialize o Swarm em um deles, e em seguida adicione os demais ao cluster.
Feito isso, precisamos criar um rede do tipo overlay, que será utilizada pelo traefik para enviar o trafego web:
docker network create -d overlay net
Depois de inicializada a rede overlay, basta criar o serviço do traefik:
docker service create --name traefik --constraint 'node.role==manager' --publish 80:80 --publish 8080:8080 --mount type=bind,source=/var/run/docker.sock,target=/var/run/docker.sock --network net traefik:camembert --docker --docker.swarmmode --docker.domain=mundodocker --docker.watch --logLevel=DEBUG --web
Com este comando, será criado um serviço mapeando o socket do Docker para que o traefik possa monitorar o que acontece neste cluster, além disso são expostas as porta 80 (para acesso dos sites/apis) e 8080 (página administrativa do traefik), caso preciso da 443, basta adicionar a lista.
Ok, até agora o que fizemos foi criar o serviço do traefik no cluster para que monitore e se reconfigure baseado nos eventos do cluster. Agora precisamos criar nossos serviços web e ver se tudo funcionará como deveria. Vamos lá:
Blog:
Vamos criar agora uma nova aplicação web, que será responsável por um blog, o processo de criação é bem simples:
docker service create --name traefik --label 'traefik.port=80' --label traefik.frontend.rule="Host:blog.mundodocker.com.br;" --network net ghost
Criamos um serviço com nome de blog, utilizando uma imagem do WordPress e adicionamos na rede “net”, essa mesma rede onde o traefik está, agora vamos detalhar os novos parâmetros:
- traefik.port = Porta onde a aplicação vai trabalhar, nos caso do wordpress, será na porta 80 mesmo.
- traefik.frontend.rule = Qual será o virtual host que este serviço atende, com isso o traefik consegue definir que, quando chegar uma requisição para: blog.mundodocker.com.br, encaminhará as requisições para o serviço correto.
Agora basta apontar no DNS a entrada blog.mundodocker.com.br para o servidor do traefik e a mágica estará feita.
Site:
Para ver como é difícil, tudo que você precisa fazer é executar este comando:
docker service create --name site --label 'traefik.port=80' --label traefik.frontend.rule="Host:www.mundodocker.com.br;" --network net tutum/apache-php
Dessa vez criamos um novo serviço, na mesma rede, mas com alguns parâmetros diferentes, como é o caso do traefik.frontend.rule, onde especificamos um novo endereço, e claro a imagem que vamos utilizar, que agora é a tutum/apache-php.
URLs:
Outra feature muito legal do traefik é a possibilidade de redirecionar URLs para backends diferentes. O que isso quer dizer? Quer dizer que podemos enviar partes de uma aplicação para serviços diversos, por exemplo, na aplicação existe um /compras e um /categoria, podemos enviar essas URLs para serviços distintos, isso apenas informando o traefik, veja:
docker service create --name categoria --label 'traefik.port=3000' --label traefik.frontend.rule="Host:www.mundodocker.com.br; Path: /categoria/" --network net node
Note que agora temos um novo parâmetro, o “Path” onde especificamos qual URL este serviço vai atender, o resto é semelhante, informamos a porta e imagem que este serviço vai utilizar. Para criar um serviço especifico para outra URL, basta:
docker service create --name compras --label 'traefik.port=3000' --label traefik.frontend.rule="Host:www.mundodocker.com.br; Path: /compras/" --network -net node
E pronto, sua aplicação estará “quebrada” entre vários serviços, e o mais legal é que você não precisou editar um arquivo de configuração se quer. Além dessas facilidades, o traefik ainda disponibiliza uma interface para visualizar como está a saúde das url, em nosso lab você acessará pela porta 8080, e você visualizará algo assim:
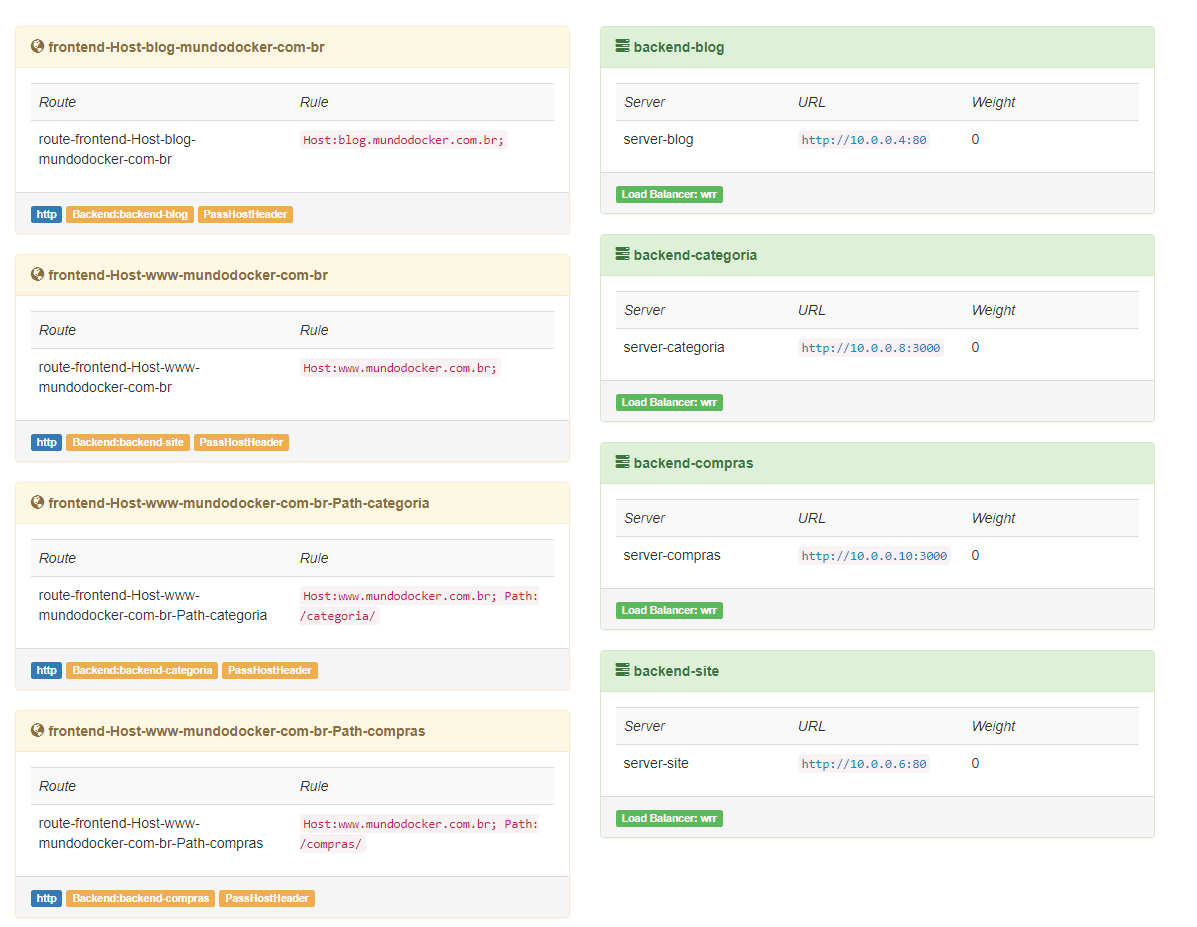
Neste dashboard você poderá visualizar como estão configuradas as suas entradas no proxy. Na aba health você poderá visualizar como está o tempo de resposta das url e saber se está tudo certo com o trafego, veja:
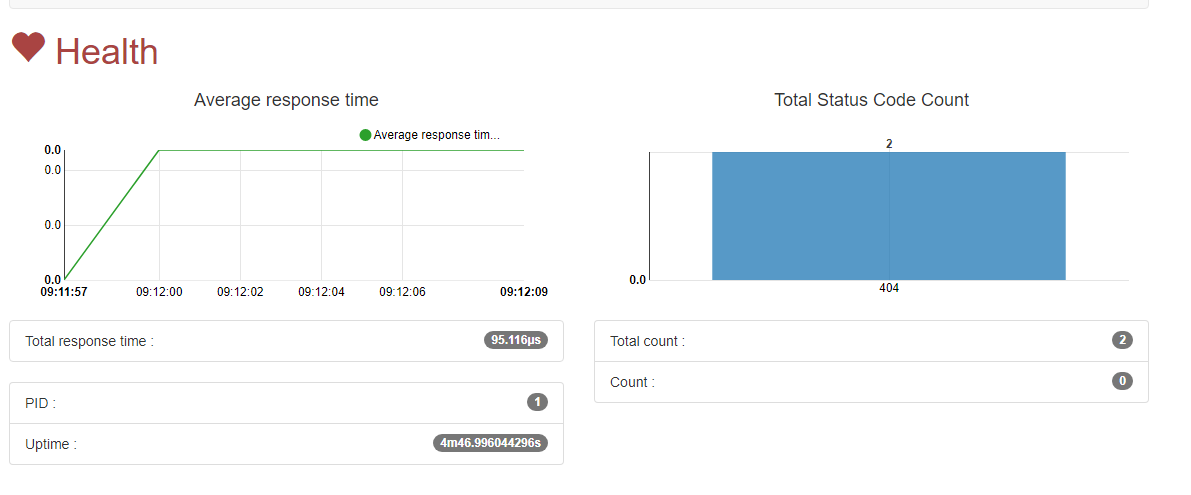
Bonito né? E além de tudo, extremamente funcional 🙂 , em posts futuros veremos um pouco mais sobre como funciona a API do traefik, como configurar o let’s encrypt, e alguns outros pontos, por enquanto, como post introdutório, era isso que gostaria de trazer a vocês.
Esperemos que tenham gostado, qualquer dúvida/sugestão nos avise 😉
Grande abraço, até mais!

Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.