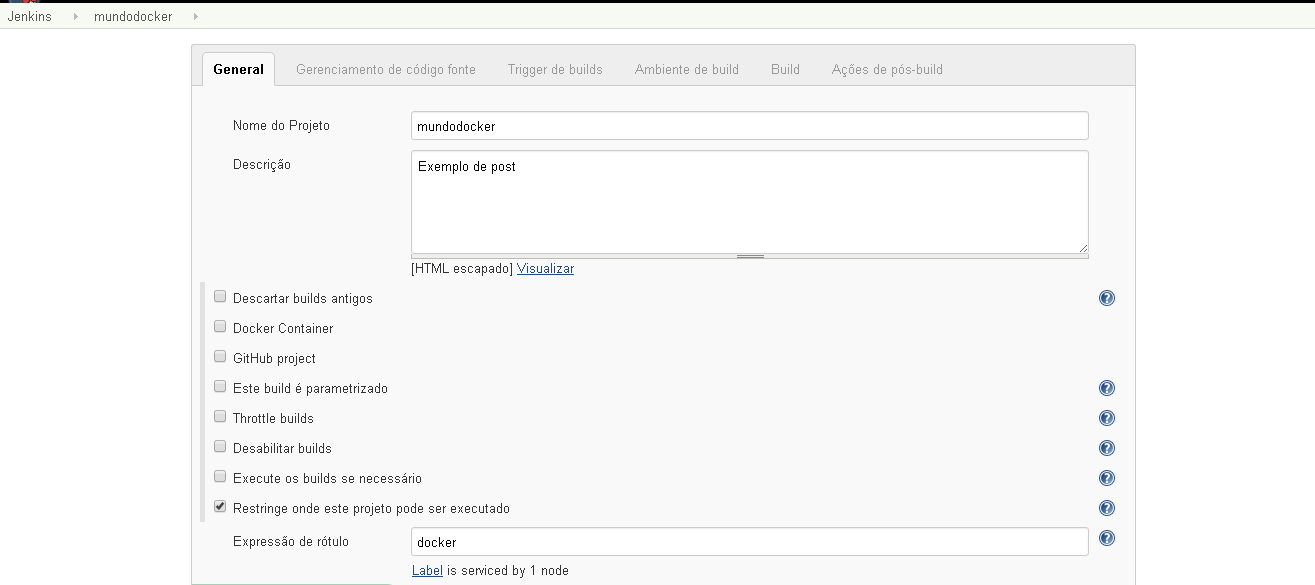
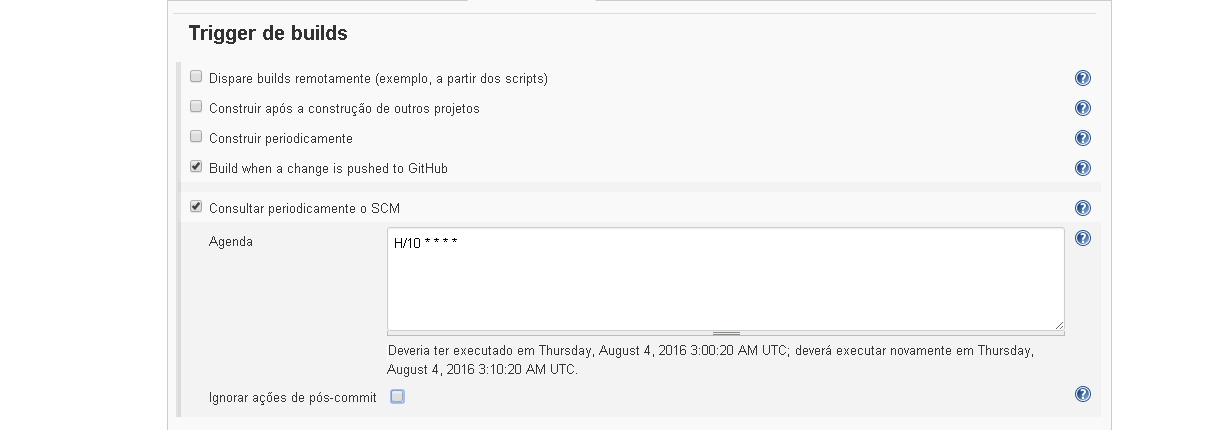
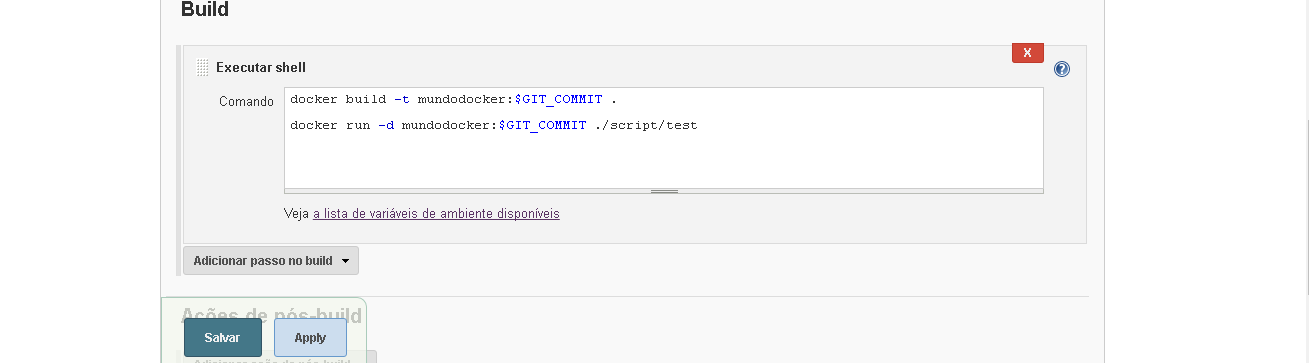
Olá pessoal,
No primeiro post da série falamos sobre AUFS e hoje vamos falar um pouco sobre Device Mapper.
Origem
No começo o Docker era suportado apenas em distribuições Ubuntu, Debian e usavam AUFS para o seu armazenamento. Depois de algum tempo o Docker começou a se popularizar e as pessoas começaram a querer utilizar Docker com RedHat, porêm o AUFS era suportado apenas em sistemas (Debian,Ubuntu).
Então os engenheiros da Redhat baseados no código do AUFS decidiram desenvolver uma tecnologia própria de armazenamento baseado no já existente “Device mapper”. Então os engenheiros da RedHat colaboraram com o “Docker inc” para contribuir com um novo driver de armazenamento para containers. Então o Docker foi reprojetado para fazer a conexão automática com o dispositivo de armazenamento baseado em Device Mapper.
Layers
O Device Mapper armazena cada imagem e container em seu disco virtual, esses discos virtuais são dispositivos do tipo Copy-on-Write no nível de bloco e não a nível de arquivo. Isso significa que ao invés do Device Mapper copiar todo um arquivo para o seu dispositivo, ele vai copiando por blocos o que o torna muito rápido comparado ao AUFS. No processo de criação de uma imagem com o Device Mapper é criado um pool e em cima desse pool é criado um dispositivo base que é a partir dele que as imagens são construídas, a partir dai temos as imagens base do Docker que a cada modificação vão criando camadas de snapshots a cima da camada anterior. Conforme a imagem abaixo:

Read
Quando um container deseja ler algum arquivo que está nas camadas anteriores o Device Mapper cria um ponteiro na camada do container referenciando a camada da imagem onde possui esses dados colocando transferindo esse bloco para a memória do container.
Write
Quando o Docker faz uma alteração no arquivo utilizando Device Mapper esse arquivo é copiado apenas o que sera modificado cada bloco de modificação copiado é de no máximo 64KB. Por exemplo na escrita de um arquivo de 40KB de novos dados para o container o Device Mapper aloca um único bloco de 64KB para o container, caso a escrita seja de um arquivo maior que 64KB então o Device Mapper aloca mais blocos para realizar essa gravação.
O Device Mapper já é padrão nas em algumas distribuições do linux como:
- RedHat/Centos/Fedora
- Ubuntu 12.04 e 14.04
- Debian
Docker e Device Mapper
O Device Mapper atribui novos blocos para um container por meio de uma operação chamada “Allocate-on-Demand”, isso significa que cada vez que uma aplicação for gravar em algum lugar novo dentro do container, um ou mais blocos vazios dependendo do tamanho de gravação terão que ser localizados a partir do pool mapeado para esse container. Como os blocos são de 64KB então muitas gravações pequenas podem sofrer com problemas de performance, pois acaba causando lentidões nas operações. Com isso aplicações que gravam arquivos pequenos sequencialmente podem ter performance piores com Device Mapper do que com AUFS.
Legal né? Se gostou nos ajude divulgando o blog.
Grande abraço!

Trabalha em uma consultoria com foco em Plataforma como Serviço (PaaS), é especialista em Cloud Computing e Conteinerização, desenvolve todo dia uma nova maneira de resolver problemas e criar coisas novas.