Olá gente! Tudo bem?
Como vocês podem ter notado, meu nome é Fernando e este é o meu primeiro post aqui no blog, e minha contribuição será no sentido de esclarecer e ajudar vocês com algumas questões que pouca gente se preocupa, ou até mesmo implementa, mas que eventualmente pode prejudicar a sua aplicação ou seu negócio, sim, hoje falaremos sobre Segurança 😉 .
A alguns meses iniciei uma busca por informações sobre segurança relacionado a Docker, pois não via quase ninguém falar, na época até pensei que era porque eu estava por fora dos grupos de discussões, mas ao ir conversando com algumas pessoas bem envolvidas com a comunidade Docker fui vendo que em português temos bem pouco sobre este assunto. Então comecei a buscar por este assunto e fui encontrando materiais em inglês, assim fui montando um compilado de materiais sobre para tentar criar uma apresentação ou artigo. Conversando com o Cristiano do Mundo Docker, que é um membro muito ativo na comunidade Docker, recebi bastante incentivo pois ele também achou que o assunto é bem importante e pouco abordado, e nesta conversa surgiu a ideia de fazer uma pesquisa com a comunidade para saber de quem está usando Docker o que estão fazendo com relação a segurança.
Foi um questionário bem simples, com 3 perguntas que foi realizado entre 14 e 25 de agosto 2017, com 36 participantes.
Primeira pergunta: Já utilizou Docker em produção?
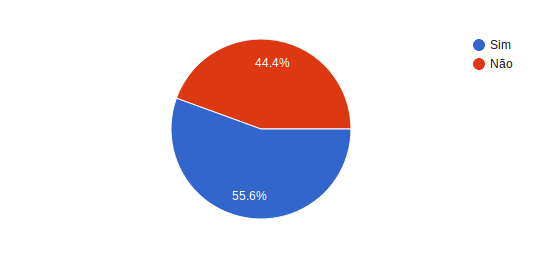
Mais de 55 por cento das pessoas que participaram da pesquisa responderam que utilizam Docker em produção.
Segunda pergunta: Verifica vulnerabilidades nas imagens utilizadas?
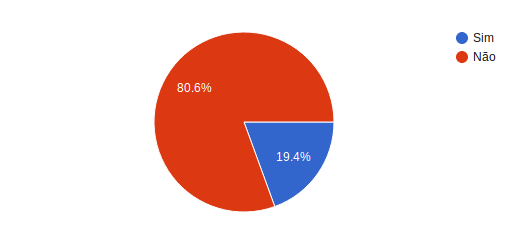
Dos 36 participantes menos de 20 por cento faz algum tipo de verificação para tentar identificar vulnerabilidades nas imagens Docker utilizadas.
Terceira pergunta: Como verificar vulnerabilidades?
E na última pergunta a ideia era identificar se é utilizado algum tipo de ferramenta para fazer as verificações de vulnerabilidades. Dos 19.4% que responderam que fazem alguma verificação somente um respondeu que utilizava alguma tipo de ferramenta, os outros informaram fazer verificações manuais, analisando o dockerfile e suas dependências, verificando autenticação, permissões e qualquer tipo de comunicação com o host.
Com base nessa pesquisa eu passei a focar o desenvolvimento deste material em ferramentas que podem ajudar no dia-a-dia para verificação de vulnerabilidades, em imagens, container e host. E com isso também encontrei ferramentas para fazer hacking de containers Docker. Para se proteger nada melhor que saber como pode ser atacado, então acompanhem até o final que vamos ter bastante dicas e ferramentas bacanas.
Mas para começarmos a utilizar as ferramentas primeiro precisamos estar ciente de algumas preocupações e práticas de segurança ao usar Docker.
Preocupações com segurança ao usar Docker
Kernel exploits (exploração do kernel)
Ao contrário de uma VM, ao usar containers o kernel é compartilhado entre todos os containers e o host, aumentando a importância de qualquer vulnerabilidade que explore o kernel.
Denial-of-service attacks (ataque de negação de serviço)
Como todos os containers compartilham recursos do kernel, se um container pode monopolizar o acesso a certos recursos, incluindo memória, ou até IDs de usuário (UIDs), pode faltar recursos para outros containers, resultando em uma negação de serviço (DoS).
Container breakouts (invasão de container)
Um invasor que tem acesso a um container não pode ter acesso a outros containers ou ao host. Se você usa root no container, você será root no host.
Poisoned images (imagens “envenenadas”)
Como você sabe que as imagens que você está usando são seguras, não foram adulteradas, e vêm de onde elas afirmam vir?
Application secrets (segredos de aplicações)
Quando um container acessa um banco de dados ou serviço, provavelmente exigirá credenciais, como um token ou mesmo usuário e senha. Se um invasor tiver acesso ao container terá acesso a estes dados.
Práticas de segurança
No tópico anterior foi levantada algumas preocupações de segurança que devemos ter ao usar containers, agora vamos ver algumas possíveis soluções para tentar resolver estes problemas.
Inicio este tópico com uma pergunta.
Como devemos armazenar dados sensíveis, como senhas, chaves privadas, tokens, chaves de APIs?
Para começar a responder esta pergunta, eu acho mais fácil e direto responder como não devemos armazenar dados sensíveis.
Não use variáveis de ambiente ou incorpore na imagem de container. É uma dica meio óbvio mas acontece e muito. Se quiserem ler sobre um caso, de utilização de credenciais incorporadas na imagem e que vazou, tem um consideravelmente conhecido que aconteceu com a IBM: IBM Data Science Experience: Whole-Cluster Privilege Escalation Disclosure.
Mas como então devemos armazenar nossas credenciais de acesso quando usamos containers? Uma ótima solução é utilizar o Docker Secrets Management.

Docker Secrets Management
O Docker Secrets funciona como um cofre onde você pode colocar coisas sensíveis lá e só quem tem a chave do cofre consegue utilizar, no caso essa chave é designada aos nós dos serviços que a chave for atribuída. Mais de como funciona pode ser visto no blog Mundo Docker – Docker Secrets.
Outras dicas de segurança menciono abaixo em forma de tópicos:
Proteja seu host
- Certifique-se de que seu host e a configuração do Docker engine sejam seguras
- Mantenha seu SO atualizado
- Impor controle de acesso para evitar operações indesejadas, tanto no host como nos containers, usando ferramentas como SecComp, AppArmor ou SELinux
Redução dos privilégios
- Tomar cuidado ao executar como root
- Crie namespaces isolados
- Limitar privilégios ao máximo
- Verifique se o container é confiável (verifique a imagem)
Alto uso de recursos do container
- Limite os recursos no kernel ou no container
- Fazer testes de carga antes de pôr em produção
- Implemente monitoramento e alertas
Autenticidade da imagem
- De onde veio?
- Você confia no criador?
- Quais políticas de segurança está usando?
- Identificação do autor
- Não use se não confia na fonte
- Use um servidor Docker Registry próprio
- Verifique a assinatura da imagem
Vulnerabilidades de segurança presentes na imagem
- Inspecionar as imagens
- Atualize para pegar novos patches de segurança
- Utilize uma ferramenta de scanner de vulnerabilidades
- Integre esse scanner como etapa do seu CI/CD
Ferramentas de análise de segurança e hacking
Até aqui vimos algumas preocupações que devemos ter e algumas soluções relacionadas a segurança quando usamos containers, agora vamos ver algumas ferramentas que podem nos auxiliar e muito no nosso dia-a-dia.
Docker Security Scanning
Anteriormente conhecido por Projeto Nautilus, a solução fornece um perfil de segurança detalhado das imagens Docker com objetivo de tornar o ambiente em conformidade com as melhores práticas. A ferramenta faz uma varredura das imagens antes de serem utilizadas e monitoramento de vulnerabilidades. Esta ferramenta está disponível no Docker Hub, Store e Cloud.
No Docker Hub por exemplo está disponível para as imagens oficiais e pode ser visto o nível de vulnerabilidade destas imagens ao acessar as tags.
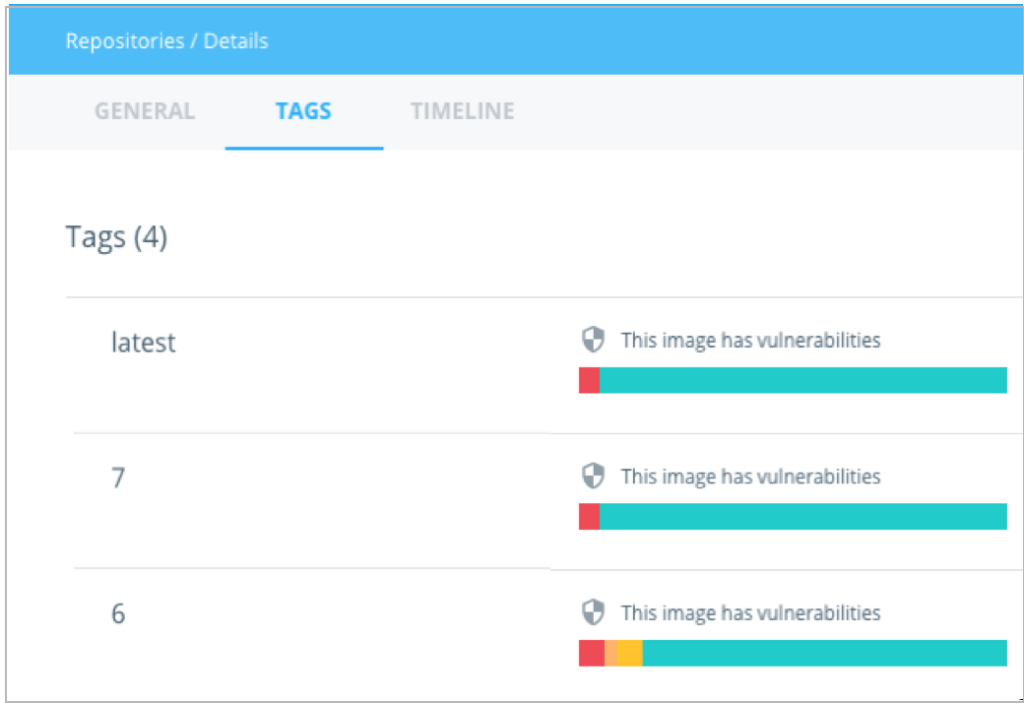
Ao clicar em uma das tags é possível identificar em qual camada está esta vulnerabilidade.
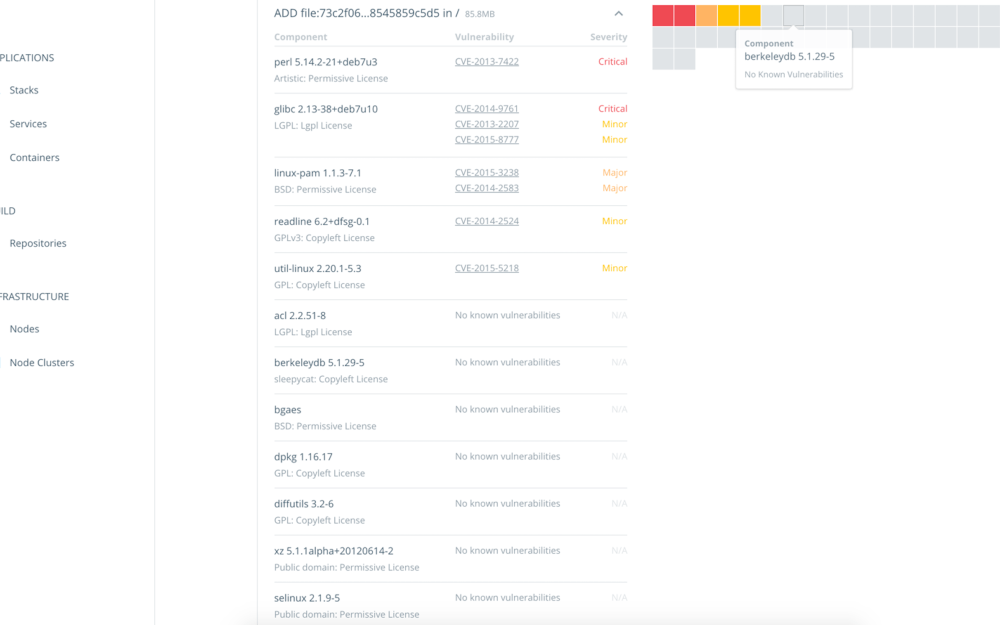
Abaixo algumas ferramentas separadas por projetos Open Source e Aplicações Web gratuitas ou pagas. São ferramentas que podem auxiliar no dia-a-dia na verificação de vulnerabilidades.
Ferramentas Web
- Anchore – anchore.io – Descubra, analise e certifique as imagens e containers
- Image Layers – imagelayers.io – Inspeciona as imagens dos containers e seus metadados
- Micro Badger – microbadger.com – Inspeciona as imagens dos containers e seus metadados
- Quay – quay.io – Constrói, analisa e distribui imagens de containers
- Twistlock – twistlock.com – Segurança para containers Docker, Kubernetes e mais
- Aqua – aquasec.com – Plataforma de segurança para containers
Ferramentas Open Source
- Clair – github.com/coreos/clair – Faz análise estaticas de vulnerabilidades em containers.
- Docker Bench for Security – https://dockerbench.com/ – O Docker Bench for Security é um script que verifica dezenas de melhores práticas comuns em torno da implantação de containers Docker na produção.
- SysDig Falco – github.com/draios/falco – Monitoramento de containers e identificação de vulnerabilidades.
- Open Scap – open-scap.org – Esta ferramenta faz revisão de imagens e containers para identificar vulnerabilidades.
- Docke Scan – github.com/kost/dockscan – Esta ferramenta faz scanner de imagens Docker para identificar vulnerabilidades.
- Docker Scan – github.com/cr0hn/dockerscan – Esta ferramenta faz scanner de imagens Docker para identificar vulnerabilidades e também possui funcionalidade para injetar vulnerabilidades.
Isso é tudo por enquanto, mas se você conhece outras dicas ou ferramentas que não são mencionadas aqui, deixe um comentário abaixo. Obrigado pela leitura e um grande abraço!
Analista de Desenvolvimento na KingHost, graduado em ADS pelo Senac. Pós-graduando em Segurança Cibernética pela UFRGS, entusiasta Open Source e Software Livre.