Oi Pessoal!
Queremos trazer para vocês hoje uma solução para coleta e visualização de métricas para o Docker Swarm. Um dos maiores desafios, principalmente para as equipes de operações, é saber quanto está sendo utilizado por cada container, OK, existem soluções na engine do Docker, como é o caso do docker stats, mas e quando você tem um diversos hosts, e eles estão em cluster e não tem definido quais containers estão em cada host, complicou né?
A intenção com este post é mostrar como é possível ter, de forma fácil, todas as informações de consumo de seu cluster, utilizando soluções simples, e que a maioria de vocês já deve ter visto. Para este lab vamos usar o Cadvisor, Influxdb e Grafana, vamos entender melhor onde cada um irá atuar neste ambiente.
Cadvisor

Como já vimos aqui no blog, o Cadvisor é uma ferramenta desenvolvida justamente para realizar a coleta de recursos de containers/aplicações dentro de um servidor. É possível estender seu uso através de integração com a API que essa ferramenta disponibiliza, e enviar os dados coletados para diversos backends, em nosso lab vamos utilizar o InfluxDB, que você verá logo abaixo o que é e como funciona.
InfluxDB

Para quem não conhece, o InfluxDB faz parte de um conjunto de soluções da empresa InfluxData, que tem seus produtos voltadas para analise, monitoramento e armazenamento de informações cronológicas. O InfluxDB é conhecido como um data series database, que serve justamente para armazenar dados em ordem cronológica.
Grafana

O Grafana talvez seja uma das mais completas ferramentas para criação e exibição de gráficos, e uma ferramenta extremamente flexível e adaptável, tendo como input diversos tipos de backend, o que facilita ainda mais o nosso lab 😉 . Você pode inclusive ter mais datasources e montar o seu dashboard unindo todas as essas informações, bacana né?
Ok, teoria é muito bonita, mas… vamos praticar?
Primeiramente você deve ter em execução o seu cluster, caso não tenha feito isso ainda, faça agora, caso tenha dúvidas, veja este post, onde mostramos na prática como fazer isso 🙂 . Certo agora vamos criar os serviços de coleta para o nosso cluster, para isso, você pode executar o seguinte passo-a-passo:
- Crie uma rede do tipo overlay para que seja possível a comunicação entra as ferramentas, e que essa comunicação seja realizada de forma isolada:
$ docker network create -d overlay --attachable coleta
- Em um dos dos hosts (de preferência o menos utilizado), crie o servidor de Influx, que será utilizado como backend para as informações coletadas:
$ docker run -d --restart=always -v /data:/var/lib/influxdb --network coleta --name influx influxdb
- Devemos criar a database dentro do influx para que seja possível salvar as informações:
$ docker exec -it influx influx -execute 'CREATE DATABASE cadvisor'- Ok, agora basta criar o serviço de coleta no cluster:
$ docker service create --name agentes --network coleta --mode global --mount type=bind,source=/,destination=/rootfs,readonly=true --mount type=bind,source=/var/run,destination=/var/run --mount type=bind,source=/sys,destination=/sys,readonly=true --mount type=bind,source=/var/lib/docker,destination=/var/lib/dockergoogle/cadvisor -logtostderr -docker_only -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influx:8086,readonly=true
Se tudo correu bem, você deve terá criado um serviço do tipo global, ou seja, cada host de seu cluster terá um container desse tipo (Cadvisor), e todos eles enviarão os dados para o banco influx. Para ter certeza de que tudo correu bem, você pode executar o comando:
$ docker service ls
Dessa forma você visualizará os serviços que estão em execução, e terá ter certeza de que os containers iniciaram em todos os nós, o retorno do comando deverá ser algo parecido com isso:
$ docker service ls ID NAME MODE REPLICAS IMAGE PORTS 5ras37n3iyu2 agentes global 2/2 google/cadvisor:latest
Viu, tudo certo 🙂 Mas ainda não acabou, continuando:
- A última etapa é subir nosso serviço de Grafana para podermos visualizar as informações que foram coletadas pelo Cadvisor, e armazenadas no InfluxDB, execute:
$ docker run -d --restart=always -v /data:/var/lib/grafana --network coleta --name grafana -p 80:3000 grafana/grafana
Simples né? Agora temos que acessar a interface do Grafana para podemos configurar e termos os gráficos que desejamos, acesse: http://ip-do-host/login, você visualizará a interface de acesso dele, como ilustrado abaixo:

Os dados de acesso default do Grafana são:
User: admin Password: admin
Estando dentro da interface do Grafana, vá até “Source” e adicione uma nova fonte de dados, nela informe “InfluxDB”, conforme imagem abaixo:
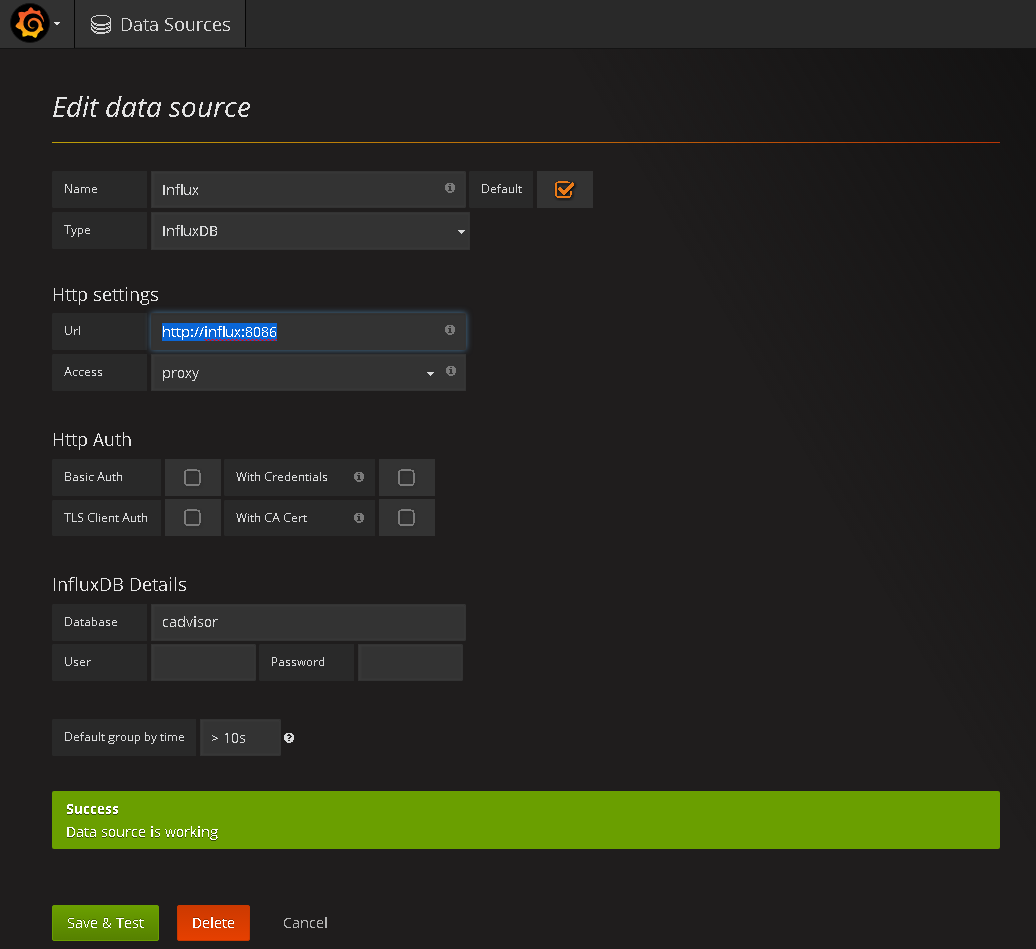
Após clique em “save & test” para validar o acesso ao seu InfluxDB. Se tudo ocorrer conforme o planejado, você terá sucesso nessa adição, e em seguida deverá montar o gráfico baseado nas informações que estão no banco, para isso existem duas formas, uma mais complexa onde você precisará montar as querys e depois criar o gráfico com essas querys, ou importar um template pronto para isso, e neste caso eu agradeço ao Hanzel Jesheen, pela contribuição a comunidade, em ter criado o template e disponibilizado em seu github 🙂 . Você pode baixar este arquivo, salvar em seu computador e depois ir até a área de Dashboard de seu Grafana e clicar em import, informe o caminho de onde salvou o template, escolha o source criado anteriormente e depois clique em “import”, conforme imagem abaixo:
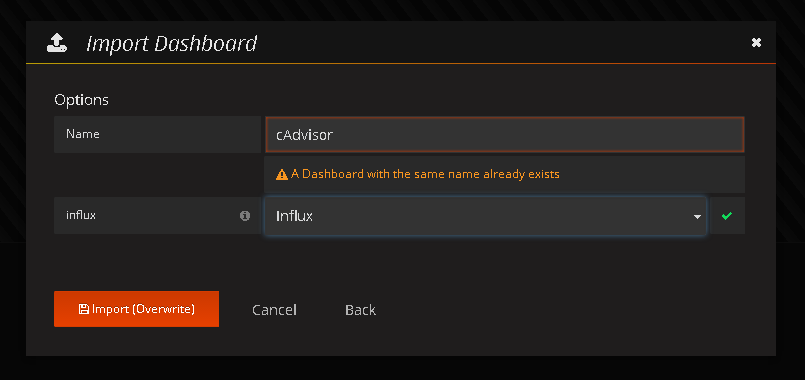
Parabéns! Você acaba de montar seu sistema de coleta e visualização de recursos para todo o seu cluster! Indo até Dashboards – Cadvisor você terá uma visualização parecida com esta:
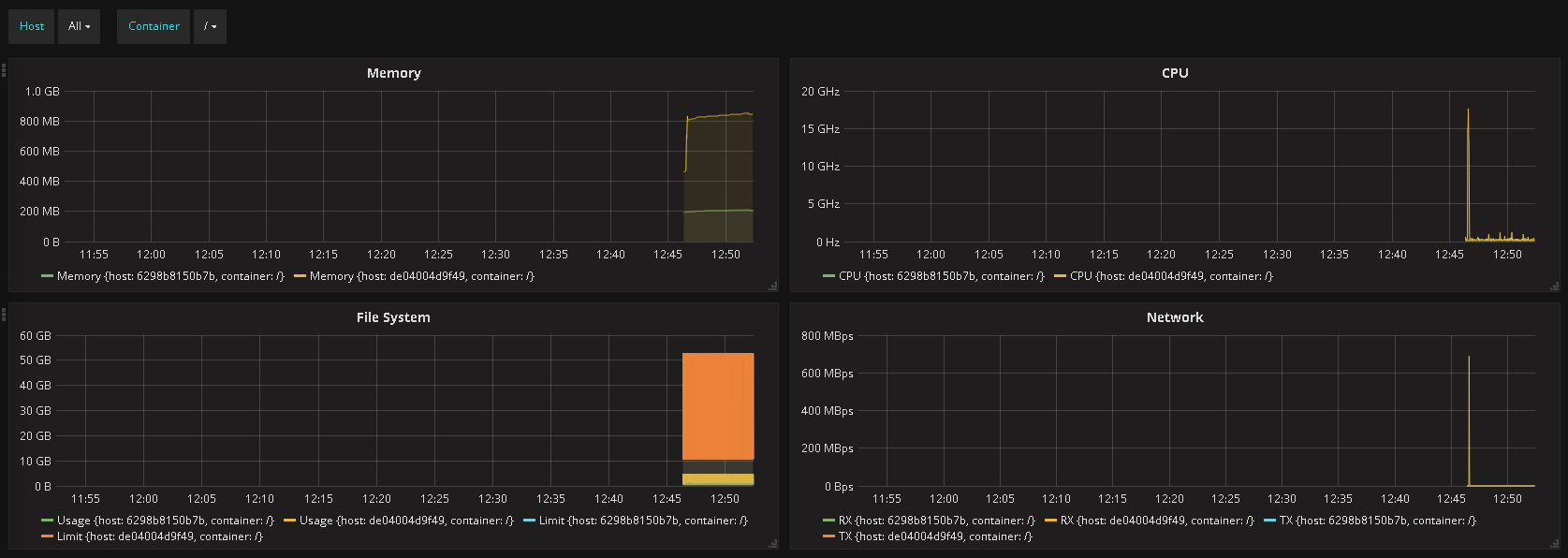
Bacana não?
A partir desse protótipo você pode evoluir seu ambiente para atender a sua demanda, em nosso lab a coleta é realizada pelo Cadvisor e enviada ao InfluxDB a cada 60 segundos, isso quer dizer que o gráfico tem um delay de 1 minuto entre a coleta e a visualização, para alguns isso é problema, para outros não. Outro ponto que você deve se atentar é: Quantos mais containers você tiver, mais poluído ficará o seu gráfico, isso por motivos óbvios, então talvez você precisa alterar o layout do dashboard. Ahhh não esqueça de trocar a senha do usuário admin do Grafana 😉
Por hoje era isso gente, esperamos que isso ajude vocês, e continuaremos com alguns posts mais técnicos trazendo alguns soluções ou implementações legais utilizando Docker. Nos ajude divulgando o blog, e tendo dúvida nos avise!
Grande abraço!

Entusiasta Open Source, seu principal foco é ir atrás de ideias novas e torna-las realidade através de soluções simples e eficientes, o menos é mais, e o dividir é multiplicar.